Realizacja usług multimedialnych w sieci WLAN 802.11b Cel: ocena możliwości realizacji usług multimedialnych w sieci bezprzewodowej wykorzystującej standard 802.11b. 1. Charakterystyka usługi multimedialnej i jej podatności na zniekształcenia czasowe oraz stratność 1.1 Właściwość usługi czasu rzeczywistego: rozwiązanie dotyczące parametrów czasowych (opóźnień, jitter) na przykładzie usługi fonicznej //(opóźnień, jitter) – niby coś jest, ale za mało, bo z wykładu 1.2 Wymagania w zakresie przepustowości łącza transmisyjnego dla usług fonicznej i transmisji obrazu //-> metody kompresji fonii i obrazu (MP3, MPEG, ),. - MPEG-2, mało o MPEG-4 i H.264 //straty -> (fe)? Pe(?) (IBER)? (BER)? - nic o tym 1.3 Właściwości usługi wideokonferencyjnej - multimedialnej 2. Metody dostępu do medium (kanału radiowego) w standardzie 802.11b.
2.1 Metoda regulacyjna dostępu CSMA/CA - DCF 2.2 Metoda regulowanego dostępu do kanału radiowego - PCF 2.3 Ocena porównawcza metod dostępu do łącza radiowego FDMA, TDMA, CSMA/CA 3. Ocena przydatności protokołu 802.11b do realizacji usługi VoWLAN 4. Wnioski 1. Charakterystyka usługi multimedialnej i jej podatności na zniekształcenia czasowe oraz stratność 1.1 Właściwość usługi czasu rzeczywistego: rozwiązanie dotyczące parametrów czasowych na przykładzie usługi fonicznej //(opóźnień, jitter) //terminale //wykład Czynniki pogarszające jakość Większość rozwiązań VoIP opiera się na zastosowaniu protokołu UDP do transmisji głosu. UDP nie gwarantuje dotarcia pakietów w określonej kolejności (używane są bufory do rekonstrukcji strumienia, co powoduje opóźnienie dotarcia pakietu w ogóle) powoduje to że opóźnienie transmisji nie jest stałe (Jitter). Utrata pakietu w VoIP W przypadku przepełnienia buforów urządzenia sieciowe odrzucają w pierwszej kolejności pakiety UDP. Odbiornik oczekuje na pakiet przez pewien określony czas (opóźnienie ulega zwiększeniu). Pakiety w VoIP nie są retransmitowane, zwiększyłoby to opóźnienie. Aby zapobiec artefaktom podczas odtwarzania strumienia audio, jest on wydłużany, najczęściej poprzez powielenie fragmentów poprzedzających utracony pakiet. Po podjęciu decyzji o tym, czy pakiet został utracony następuje próba rekonstrukcji danych np. poprzez predykcję liniową (w przód i w tył – na podstawie poprzedzających i kolejnych pakietów) lub nieliniową (np. sieć neuronową). W efekcie utraty pakietu zostaje zaburzona liniowość osi czasu strumienia audio, pojawia się Jitter. Pewne typy kodeków (np. kodeki ADPCM) wykorzystują informację z poprzednich ramek do odtworzenia kolejnych, utrata pakietu powoduje znaczne pogorszenie jakości sygnału. Opóźnienie transmisji Standardem telekomunikacyjnym jest opóźnienie rzędu 35ms. W sieci VoIP jest to praktycznie nie do zrealizowania, duży wpływ na to ma np. konstrukcja systemu operacyjnego (minimalne opóźnienie w Windows to 10ms). Dodatkowe opóźnienie jest generowane przez kodek. Z tego powodu, pod kątem VoIP opracowuje się specjalne kodeki o niewielkim opóźnieniu. Opóźnienie większe niż 200 milisekund powoduje znaczny dyskomfort i utrudnia zrozumienie. Jitter Efekt zmiennego w czasie opóźnienia – niektóre ramki są „rozciągane” w czasie poprzez powielenie, inne – skracane poprzez miksowanie. Powoduje to wrażenie „pływania” dźwięku, jest to najistotniejszy czynnik pogarszający jakość w VoIP. Echo W klasycznej telefonii występują dwa rodzaje echa: hybrydowe i akustyczne. W VoIP echo hybrydowe nie występuje, jest związane z fizycznym interfejsem kablowym. Echo akustyczne jest związane ze sprzężeniem akustycznym między głośnikiem i mikrofonem. W VoIP echo akustyczne ma dwa źródła:
Wykorzystanie zestawów głośnomówiących wraz z mikrofonami do-okólnymi.
Opóźnienia związane z transmisją w sieci IP (pakietyzacja, kolejkowanie).
Powszechne jest użycie tzw. echo - canceller'ów. Istnieje szereg standardów telekomunikacyjnych definiujących algorytmy usuwania echa: G.165, G.168. Algorytmy te opierają się na filtracji adaptacyjnej sygnału odbieranego. Jest to proces kosztowny obliczeniowo, dlatego echo jest usuwane tylko w krótkim okresie czasu (do 64-128ms). Kodeki VoIP utrudniają usuwanie echa poprzez wprowadzane zniekształcenia. Istnieją dwa rodzaje echo - canceller'ów:
Działające tylko w oparciu o sygnał odbierany.
Działające w oparciu o sygnał odbierany i nadawany.
Niektóre kodeki zawierają w sobie mechanizmy usuwania echa (np. Speex) ale ich skuteczność jest niska. Problem jest poważny, jedną z przyczyn popularności Skype jest właśnie efektywne usuwanie echa. Microsoft wbudował echo - canceller w system Windows XP (DirectX) aby ułatwić tworzenie systemów VoIP. Ograniczona przepływność W warunkach ograniczonej przepływności jakość głosu pogarsza się w związku z częstszymi utratami pakietów, dlatego dąży się do minimalizacji przepływności wymaganej przez transmisję VoIP zwiększając kompresje. Mniejsza przepływność wymagana oznacza większą równoczesną liczbę transmisji. Konstrukcja protokołu IP powoduje, że nie jest opłacalne zmniejszanie przepustowości poniżej pewnych wartości – nagłówki IP / UDP / RTP zajmują więcej miejsca niż same transmitowane dane. Protokół IPv4 jest kiepskim medium dla telefonii VoIP. //terminale //wykład //Interaktywne usługi głosowe VoIP
1 Wprowadzenie
Technologia VoIP i jej zastosowania
Ostatnie lata bez wątpienia nazwać można erą internetu. Globalna sieć stała się niemal nieodzownym elementem ludzkiego życia, sprawiając że pojęcie globalnej wioski nabrało realnego znaczenia. Nic dziwnego, że wiele starszych technologii komunikacyjnych zostaje wyparta poprzez nowe, lepsze media. Pocztę tradycyjną zastępuje elektroniczna, nośniki dźwięku wypierane są przez sklepy internetowe z muzyką zapisaną w formatach MP3, a kontakty międzyludzkie upraszczane poprzez komunikatory internetowe, a od niedawna także przez telefonię internetową.
VoIP (ang. Voice over IP) zyskał ogromną popularność dzięki głosowym komunikatorom internetowym, takim jak Skype, Gizmo czy Gtalk, jednakże dopiero wraz ze standaryzacją protokołu SIP w wersji drugiej, telefonia IP mogła zacząć konkurować z tradycyjnymi sieciami komutowanymi oraz ISDN. Nic w tym dziwnego, bowiem VoIP jest technologia, która wypełnia lukę w świecie internetu. Ogromną popularność tejże technologii można paradoksalnie zawdzięczać krajom mniej rozwiniętym technologicznie oraz tym, w którym ceny tradycyjnych usług telekomunikacyjnych są bardzo wysokie. Przykładem może być Rumunia lub Afganistan. Kraje te, mimo ze zlokalizowane w rożnych rejonach świata, posiadały mało rozwinięta, lub przestarzałą sieć telefoniczną. Równocześnie internet rozwijał się tam na tyle dynamicznie, że nastąpiła sytuacja, że mieszkaniec miał łatwiejszy dostęp do sieci internetowej, niż do wysokiej jakości telefonii. Wypełnienie powstałej niszy przez telefonie IP było tylko kwestią czasu.
Innym motorem napędzającym rynek VoIP były kraje, gdzie ceny za usługi telekomunikacyjne były lub do dziś są bardzo wysokie. Przykładem jest Polska, gdzie krajowy operator, utrzymuje jedne z najwyższych cen w Europie za minutę połączenia, jednocześnie blokując skutecznie rozwój alternatywnych firm telekomunikacyjnych poprzez drogie połączenia między-operatorskie. W szybkim czasie operatorzy telefonii IP zdobyli cześć rynku usług telekomunikacyjnych, oferując dodatkowo wiele usług dostępnych normalnie jedynie w zaawansowanych sieciach cyfrowych ISDN i to za dodatkowymi opłatami. Dzięki temu, że ceny za minutę połączenia w VoIP są w małym stopniu zależne od cen operatorów tradycyjnych, a także przez brak wydatków na budowę drogiej infrastruktury sieci, ceny mogły być w znacznym stopniu obniżone.
Po użytkownikach końcowych, VoIP został zauważony przez firmy, jako obniżenie nie tyle kosztów samych połączeń, ale oszczędności związanych z inwestycją w infrastrukturę - kable, telefony, centrale. Jednocześnie okres ten był także 'boomem' usług outsourcingowych, firmy zaczęły dostrzegać zalety oraz profity zlecenia usług na zewnątrz. W najbardziej ekstremalnych przypadkach, firma nie musi posiadać nic prócz komputerów oraz dostępu do internetu, by w pełni korzystać z wszystkich usług oferowanych przez drogie centrale tradycyjne. Także firmy telekomunikacyjne, a w szczególności operatorzy GSM zauważyli VoIP jako alternatywne rozwiązanie przesyłania danych pomiędzy stacjami nadawczymi. Jako pierwsza z tego typu rozwiązań skorzystała w Polsce siec Era GSM. Nie inaczej sprawa miała się z tradycyjnymi operatorami telefonicznymi, którzy masowo zaczęli terminować (przekierowywać?) drogi ruch do sieci komórkowych poprzez operatorów telefonii IP. Dziś kupując kanały ISDN, klient nie jest świadomy, ze większa cześć połączeń międzynarodowych oraz do sieci komórkowych realizowana jest przez siec IP.
Technologia VoIP nie ominęła także e-biznesu oraz producentów oprogramowania dedykowanego. Coraz więcej firm integruje swoje produkty z centralami SIP, producenci systemów klasy B2B oraz B2C dopiero zaczynają poznawać możliwości jakie niesie integracja VoIP z ich produktami. W najbliższej przyszłości można spodziewać się rozkwitu na tej płaszczyźnie.
Nie byłoby jednak rozwoju bez odpowiednich narzędzi o szerokiej dostępności. Wielki wpływ na popularność telefonii internetowej miało środowisko Open Source. Oprogramowanie takie jak Asterisk, OpenSER, SER, sipX czy Yate pozwala niskim kosztem zbudować własne systemy telefonii IP i stopniowo dodawać kolejne usługi. Podsumowując, VoIP jest technologią ważna i perspektywiczną, jest to bez wątpienia jedna z najważniejszych usług sieci internet, która dopiero zaczyna swoją globalną ekspansję na wszystkie sfery e-życia.
2 Technologia VoIP
Wstęp
Cześć ta ma na celu ogólne wprowadzenie w problematykę związaną z technologia VoIP. Omówione zostaną najważniejsze protokoły realizujące sieci VoIP, metody kompresji głosu ludzkiego oraz wykorzystanie pasma.
Protokół SIP
SIP (ang. Session Initiation Protocol), protokół inicjowania i zarządzania sesjami został zaprojektowany przez IETF (ang. Internet Engineering Task Force) i po raz pierwszy stał się standardem w roku 1999 w dokumencie RFC 2543. W późniejszym czasie, dokonano zmian i modernizacji w protokole, co poskutkowało standardem RFC 3261, który potocznie znany jest pod nazwą SIP 2.0. Aktualnie SIP jest najbardziej rozprzestrzenionym protokołem używanym w sieciach VoIP i docelowo ma zastąpić H323, zbiór protokółów wzorowanych na sieciach ISDN. Za ciekawostkę należy uznać fakt, że SIP jest pierwszym protokołem stworzonym przez środowisko internetowe, a nie telekomunikacyjne, co uważane jest za jedna z cech, które przyczyniły się do jego sukcesu.
Z puntu widzenia sieci komputerowych i protokołów sieciowych, SIP umiejscowiony jest w warstwie aplikacji modelu ISO/OSI, tak jak protokół HTTP, na którym SIP był częściowo wzorowany. Oba posiadają czytelną dla człowieka budowę, poprzez używanie otwartego tekstu w pakietach, identyfikacje zasobów dzięki używaniu formatu URI (sip:username@server:port ,np. sip:joe@sip.server.com:5060), oraz podobny sposób opisu błędów. Session Initiation Protocol kojarzony jest głównie z telefonia VoIP, jednakże równie dobrze może być użyty do zestawiania jakichkolwiek sesji pomiędzy klientami. Istnieją projekty, gdzie SIP kontroluje przesyłanie wiadomości w komunikatorach internetowych, transmisje video czy sesje w chatach online.
Sam protokół SIP odpowiedzialny jest jedynie za zarządzanie zestawieniem sesji pomiędzy użytkownikami. Nie przenosi on danych w niej przysyłanych, a jedynie jej opis, za który odpowiedzialny jest protokół SDP. Takie rozwiązanie gwarantuje wynegocjowanie warunków, dzięki którym zainicjowanie sesji się powiedzie. W szczególności, w VoIP, ważne jest aby obie strony użyły tego samego kodeka głosu, odpowiednich portów, czy adresów IP.
Do pozytywnego zestawienia sesji poprzez SIP, zakładając że negocjacja przebiegła pozytywnie, wystarczą tylko dwa urządzenia lub programy klienckie, jednakże najczęściej spotykane sieci SIP mogą zawierać cztery elementy:
Agenty SIP - (ang. user agents) urządzenia używające SIP do zestawienia sesji pomiędzy sobą, mogą nimi być zarówno urządzenia z zaimplementowanym stosem SIP, takie jak telefony IP, telefony komórkowe typu smartphone, jak też aplikacje komputerowe rezydujące w systemie operacyjnym.
Serwery Pośredniczące SIP - (ang. proxy server) urządzenia lub oprogramowanie, których podstawową funkcją jest realizowanie routing'u wiadomości SIP, pomiędzy domenami SIP. Można myśleć o nich analogicznie jak o router'ach w sieciach IP. Wyróżnia się dwa rodzaje serwerów proxy, serwery stanowe - (ang. stateful proxy) utrzymują informacje o sesji do jej zakończenia, co umożliwia wykonanie pewnych akcji bazując na historii połączenia. W przeciwieństwie do serwerów bezstanowych, które przekazują jedynie pakiety sesji, bez utrzymywania historii o niej.
Serwery rejestracji - (ang. SIP Registrar server) jednostki odpowiedzialne za rejestracje agentów
użytkowników, zapisujące adres IP i port pod jakim agent jest osiągalny.
Serwery przekierowań - (ang. redirect server) jednostki odpowiedzialne za odbiór wiadomości i
wysyłanie wiadomości przekierowujących zadania agentów do innych lokacji.
W nowoczesnej infrastrukturze SIP, serwery przekierowań zespolone są przeważnie z serwerami proxy.
Rys. 1: Zobrazowanie typowej sesji z wykorzystaniem infrastruktury protokołu SIP.
Powyższy diagram, pokazuje jak wygląda przykładowa sesja realizowana za pomocą protokołu SIP. Wykorzystuje ona dwa agenty użytkownika, serwer rejestracji oraz serwery proxy. Po zestawieniu sesji następuje transmisja danych, pomiędzy agentami, dla uproszczenia można przyjąć, że jest to transmisja głosu w sieci VoIP, jednakże równie dobrze mogą to być dane tekstowe, strumień video czy pliki. Aby przykład był jak najbardziej reprezentatywny, założono, że użytkownik 2, w przeciwieństwie do użytkownika 1, rejestruje się w serwerze rejestracji. Faktyczny początek sesji następuje, gdy agent 1, wysyła początkowy komunikat SIP INVITE, który jest swego rodzaju “zaproszeniem”, do zestawienia połączenia z agentem B. Komunikat INVITE, wysyłany jest do serwera proxy domeny domena-1.com, w której agent 1 się znajduje. Serwer, na podstawie pakietu INVITE, stwierdza ze użytkownik 2, do którego pakiet ma zostać posłany, znajduje się w domenie domena-2.com, przekazuje zatem pakiet odpowiedniemu serwerowi proxy, w tejże domenie, a ten do użytkownika 2. W tym samym czasie następuje propagacja komunikatów kontrolnych:
• 100 Trying - potwierdzającego, że pakiet INVITE zostaje przesyłany, oraz,
• 180 Ringing - mówiącego o tym, że użytkownik 2 został znaleziony i następuje faza oczekiwania na potwierdzenie z jego strony. W szczególności, w VoIP, ten typ komunikatu powoduje, ze telefon użytkownika 2 dzwoni, a użytkownik 1 słyszy tak zwany sygnał progresu (oczekiwania na zestawienie połączenia).
Po wymianie komunikatów, następuje zestawienie sesji mediów. Moment ten unaocznia wyraźnie czysto sygnalizacyjny charakter protokołu SIP. Elementy infrastruktury odgrywają rolę jedynie w nawiązaniu sesji, jakkolwiek sama wymiana danych, jak i sygnalizacja końcowa odbywa się już jedynie pomiędzy agentami końcowymi. Wadą takiego rozwiązania są trudności w komunikacji pomiędzy agentami, z których przynajmniej jeden znajduje się za NAT-em. Dodatkowym faktem mogącym świadczyć o potencjalnym problemie jest to, że komunikacja SIP odbywa się za pomocą protokołu UDP.
Po wspomnianym zestawieniu sesji, następuje wymiana danych. W technologii VoIP, oczywistym faktem jest, że jest to transmisja głosu, skompresowana za pomocą kodeków. RTP jest protokołem zapewniającym przepływ strumienia w sieci IP, może korzystać zarówno z TCP jak i UDP, jako transportu. Charakter sieci IP, czy w ogólności Internetu powoduje wiele problemów jakościowych w przesyłaniu dźwięku oraz transmisji faksowej. Tradycyjne sieci telekomunikacyjne, a w szczególności PSTN, używają transmisji synchronicznych z zegarem, daje to gwarancje, że próbki dźwięku docierają w wiadomych i przewidywalnych oknach czasu. W sieciach IP, nie można tego zapewnić, dlatego ożywa się dodatkowych protokołów, takich jak RTCP dla dźwięku, czy standard T38 dla faksów.
Poniżej, przedstawiony jest przykładowy pakiet SIP INVITE. Pierwszy wiersz mówi, że typ komunikatu to INVITE. Zawiera także URI żądania (ang. Request URI). W tym przypadku pakiet wysyłany jest do użytkownika 2 w domenie domena-2.com. Nagłówek Via mówi o hoście następnym na drodze wiadomości (ang. next-hop). Przeważnie jest to serwer proxy dla danej domeny. Pola From: oraz To:, analogicznie jak w protokole SMTP (ang. Simple Mail Transfer Protocol), wskazują od kogo oraz do kogo kierowana jest wiadomość. Call-ID działa jak znacznik sesji, dla wszystkich komunikatów w ramach jednej rozmowy jest taki sam, w odróżnieniu od CSeq, który numeruje kolejne wiadomości, które przesyłane są po niepewnych łączach i mogą dochodzić do celu w różnej kolejności. Pole Contact zawiera adres IP oraz port, na którym urządzenie, czy aplikacja źródłowa oczekuje na odpowiedź. User-Agent, jak sama nazwa wskazuje, zawiera nazwę i opcjonalnie wersję oprogramowania, lub urządzenia, z którego następuje komunikacja. Po części nagłówkowej pakietu, jest ciało wiadomości. W tym przypadku jest to pakiet protokołu SDP, informujący drugą stronę o kodekach, którymi dysponuje strona pierwsza.
INVITE sip : two@domena -2. com SIP /2.0
Via: SIP /2.0/ UDP 195.37.77.100:5040; rport
Max - Forwards : 10
From : "one " <sip : one@domena -1. com >; tagi =76 ff7a07 -c091 -4192 -84 a0 -
d56e91fe104f
To: <sip: two@domena -2. com >
Call -ID: d10815e0 -bf17 -4 afa -8412 - d9130a793d96@213 .20.128.35
CSeq : 2 INVITE
Contact : <sip :213.20.128.35:9315 >
User - Agent : Windows RTC /1.0
Proxy - Authorization : Digest username =" one ", realm =" domena -1. com",
algorithm =" MD5", uri =" sip: one@domena -1. com",
nonce ="3 cef753900000001771328f5ae1b8b7f0d742da1feb5753c ",
response ="53 fe98db10e1074
b03b3e06438bda70f "
Content - Type : application /sdp
Content - Length : 451
v=0
o= jku2 0 0 IN IP4 213.20.128.35
s= session
c=IN IP4 213.20.128.35
b=CT :1000
t=0 0
m= audio 54742 RTPi /AVP 97 111 112 6 0 8 4 5 3 101
a= rtpmap :97 red /8000
a= rtpmap :111 SIREN /16000
a= fmtp :111 bitrate =16000
a= rtpmap :112 G7221 /16000
a= fmtp :112 bitrate =24000
a= rtpmap :6 DVI4 /16000
a= rtpmap :0 PCMU /8000
a= rtpmap :4 G723 /8000
a= rtpmap : 3 GSMi /8000
a= rtpmap :101 telephone - event /8000
a= fmtp :101 0 -16
Rys. 2: Pakiet SIP INVITE.
Oprócz komunikatu INVITE, wyróżnia się także :
ACK - używany do zatwierdzania komunikatów INVITE.
BYE - terminuje sesje mediów.
CANCEL - terminuje nie do końca, nawiązaną sesje.
REGISTER - wysyłany do serwera rejestracji, zawiera informacje o lokacji użytkownika.
W protokole SIP, podobnie jak w HTTP, odpowiedzi są w formie numerycznych kodów. Każda setka, począwszy od 100, oznacza inny typ odpowiedzi:
1xx - odpowiedzi informacyjne, informujące o statusach przetwarzania.
2xx - odpowiedzi o pozytywnym, finalnym zakończeniu przetwarzania.
3xx - odpowiedzi używane do przekierowywania, informują o nowej lokalizacji użytkownika, lub dodatkowych wymaganiach, które użytkownik wysyłający pakiet musi spełnić.
4xx - odpowiedzi negatywne, oznaczające problem po stronie docelowej.
5xx - odpowiedzi informujące o problemie po stronie serwera, w przypadku gdy żądanie jest poprawne, ale serwer nie jest w stanie go obsłużyć.
6xx - kody oznaczające, że żądanie nie może zostać obsłużone przez żaden serwer.
Standard H.323
H.323 jest zbiorem standardów ITU-T, definiujących protokoły i metody przesyłania danych głosowych oraz obrazu w sieciach pakietowych, takich jak IP. Po raz pierwszy opublikowany w roku 1996, z naciskiem na prowadzenie video konferencji w sieciach LAN. Przemysł oraz producenci sprzętu szybko zaadoptowali go także do sieci WAN oraz Internetu. Przez lata H.323 był udoskonalany i rozszerzany, tak by lepiej współpracował z sieciami pakietowymi. H.323 jako pierwszy standard zaadoptował RTP jako protokół transportowy danych audio oraz video w sieciach IP.
//lepszy wstęp z wideokonferencji
Jest to bardzo rozpowszechniona technologia, wspierana przez wielu producentów sprzętu telekomunikacyjnego oraz oprogramowania. Istnieje także sporo rozwiązań Open Source, takich jak Ekiga, X-Meeting czy GNU Gatekeeper. Należy nadmienić, że protokoły z rodziny H.32X adresują nie tylko przesyłanie danych w sieciach pakietowych, ale także ISDN, PSTN, SS7 czy 3G. Infrastruktura H.323 jest bardzo złożona, posiada o wiele więcej elementów niż omawiana wcześniej infrastruktura SIP.
Na elementy infrastruktury H.323 składają się:
Terminale - koncówki klienckie, telefony IP, lub wyspecjalizowane oprogramowanie posiadające stos H.323.
MCU - (ang. Multi Control Unit) spełnia role mostku konferencyjnego spotykanego w tradycyjnych sieciach telefonicznych, z tą różnicą, że posiada możliwość przesyłania także obrazu.
Gateway - brama łącząca sieci oparte na H.323 z innymi sieciami, takimi jak SIP, PSTN, ISDN, ale także protokołami H.324 i H.320.
Gatekeeper - wyspecjalizowane urządzenie, spełniające rolę poboczną. Może być wykorzystywane jako serwer usług dla innych elementów infrastruktury H.323. Zapewnia między innymi usługi związane z adresacją, rejestracją, uwierzytelnianiem, itd. Można go porównać w pewnym stopniu do SIP Registrar.
Elementy brzegowe - (ang. Border Elements) są to elementy infrastruktury H.323 spełniające rolę nadzorców pewnej tzw. strefy, która jest pod kontrolą jednej organizacji. Funkcjonalnie elementy brzegowe przypominają elementy gatekeeper.
W standardzie H.323, istnieje wyspecjalizowana i skomplikowana struktura sygnalizacji.
W porównaniu do protokołu SIP, gdzie za całą sygnalizacje odpowiada sam protokół SIP, w H.323 wyróżnione są dwa protokoły sygnalizacyjne. Pierwszy z nich to sygnalizacja H.225.0, używana do komunikacji z gatekeeper'ami oraz nawiązywania połączeń pomiędzy elementami infrastruktury H.323. Końcówki natomiast używają protokołu RAS. Jest to bardzo prosty protokół, składający się z niewielu komunikatów:
• Wiadomości przesyłane do Gatekeeper'a (GRx)
• Wiadomości rejestracji (RRx)
• Wiadomości wyrejestrowania (URx)
• Wiadomości dostępu (ARx)
• Przyznanie pasma (BRx)
• Wyłączenie się z komunikacji (DRx)
• Wiadomości dotyczące lokalizacji (LRx)
• Wiadomości informacyjne (IRx)
• Żądanie w toku (RIP)
• Dostępność zasobu (RAx)
• Kontrola usługi (Scx)
Dla przykładu, gdy końcówka zostaje włączona do sieci, a jej stos zainicjowany, wysyłana jest wiadomość, mająca na celu zidentyfikowanie pobliskich gatekeeper'ów - GRQ. Jeśli końcówka posiada zapisaną lokację gatekeeper'a na sztywno, wiadomość GRQ jest pomijana i od razu wysyłana jest wiadomość RRQ - żądanie rejestracji. Gatekeeper powinien odpowiedzieć wiadomością GCF, potwierdzającą otrzymanie wiadomości, oraz RCF - wiadomością potwierdzającą rejestrację. Od tego momentu terminal może nawiązywać połączenia. Służy ku temu wiadomość ARQ, na którą odpowiedzią jest ACF. Po nawiązaniu rozmowy, końcówka może nawiązać dodatkową sesję z wykorzystaniem protokołu H.324, zapewniającym szersze sterowanie przebiegiem rozmowy czy konferencji.
Rys. 3: Stos protokołów H.323
//zmiksować z wideokonferencją
Metody kompresji mowy
//1.2
W tradycyjnej telefonii analogowej, głos ludzki przesyłany jest jako impulsy elektryczne biegnące w przewodzie. Z zasady nie różni się on niczym od tego jak przesyłany jest głos w kablu od np. słuchawek stereo.
W technologiach VoIP, medium stanowi sieć IP, która jako sieć pakietowa, jest nieprzewidywalna (dowolna kolejność nadchodzących pakietów). Dodatkowo w infrastrukturze SIP, protokół RTP , wykorzystywany do transportu głosu używa w większości przypadków protokołu UDP, a próbki głosu kodowane są przez tzw. kodeki. Najpopularniejsze z nich, wykorzystywane w większości urządzeń wykorzystywanych na rynku, to:
GSM - grupa kodeków wykorzystywanych w standardzie GSM.
Cechuje je minimalne zapotrzebowanie na pasmo.
W wersji full-rate 13 kbit/s, a w wersji half-rate 5,6 kbit/s.
G.711u/a (ulaw/alaw) - najbardziej popularne kodeki zdefiniowane przez ITU-T.
Znane także jako kodeki PCM (ang. Pulse Code Modulation), z uwagi na sposób modulacji. Kodeki te wykorzystują pasmo 64 kbit/s, co wynika z próbkowania 8000 na sekundę. Każda z próbek jest wielkości 8 bit, co daje dokładnie 64 kbit w jednej sekundzie. Standard ulaw wykorzystywany jest głównie w Ameryce Północnej i Japonii, natomiast standard alaw w Europie i większości innych państw poza USA. Uważa się, że jest bardziej udany, gdyż potrzebuje mniejszej mocy obliczeniowej niż ulaw.
G726 - kodek podobny do G.711, jednakże wykorzystujący adaptacyjną różnicowa odmianę kodowania PCM. Wyróżniane są cztery możliwe pasma, zależne od wielkości próbki: 16, 24, 32 oraz 40 kbit/s. Jednakże najczęściej wykorzystywane jest pasmo 32 kbit/s.
G729 - jeden z najnowszych kodeków, cechujący się niską zajętością pasma – 8 kbit/s. Używa kodowania CS-ACELP, został opatentowany przez firmę Sipro. Mankamentem tego systemu kodowania jest to, że nie radzi on sobie z transportem znaków DTMF oraz transmisją faksów.
ILBC - (ang. Internet Low Bit Rate Codec) - jest darmowym kodekiem, stworzonym przez Global IP Sound, szeroko wykorzystywanym w znanym oprogramowaniu, takim jak Skype, Gizmo, GoogleTalk. Wykorzystuje kodowanie blokowe, przewidywania liniowego.
Speex - jest to darmowy kodek stworzony przez społeczność internetową, oparty na licencji BSD. Kodek ten jest kodekiem stratnym, oznacza to, że kompresja zachodzi kosztem jakości próbki. Jako nieliczny z kodeków, był on tworzony specjalnie z myślą o technologii VoIP, używa kodowania CELP.
Wymieniając metody kompresji głosu, należy wymienić także specyfikowane protokoły / kodeki, używane do przesyłania transmisji faksowej w sieciach VoIP. W początkowej fazie rozwoju telefonii IP, faksy przesyłane były tak samo jako głos ludzki. Używano do tego przeważnie kodeków G.711, z uwagi na wysoką jakość oraz niskie zapotrzebowanie na pasmo. Okazało się, że transmisja faksów jest bardziej podatna na błędy i wrażliwsza niż mowa ludzka. Ma na to wpływ wiele czynników. Siec IP nie gwarantuje, że kolejne części faksu dotrą do maszyny odbierającej w danym czasie i kolejności. W efekcie zdarza się, że faks nie dochodzi, lub dociera w formie niemożliwej do odczytania przez człowieka. Następuje zatem przekłamanie wiadomości. W przypadku mowy ludzkiej, pewne niedociągnięcia, korygowane są przez cześć mózgu ludzkiego, odpowiedzialnego za przetwarzanie mowy. Warunkami idealnymi dla transmisji faksowej po IP jest sytuacja, gdy łącze internetowe po obu stronach jest dobrej jakości, o gwarantowanej przepływności. Nieoczekiwanie, okazało się, że znaczenie ma czynnik taki jak jakość energii elektrycznej, jaką zasilane są bramy VoIP oraz maszyny faksowe. Odpowiedzią na te problemy stał się standard T.38 ITU-T, definiujący sposób przesyłania faksów w sieciach pakietowych używając do tego protokołów TCP i UDP. Główną ideą T.38 było wykorzystanie natywnych protokołów budujących sieć Internet w celu przesyłania faksymiliów (?). Główną zaletą tego protokołu jest zapewnienie gwarancji, ze pakiety dotrą do celu, poprzez prosty mechanizm powtarzania. Standard nie definiuje ilości powtórzeń danego pakietu, zatem może zdarzyć się, że pakiet zostanie wysłany wiele razy. Właśnie dlatego T.38 uważany jest za protokół, który “marnuje” pasmo.
Rys. 4: 4-bitowe kodowanie PCM oraz oryginalny przebieg analogowy.
//Interaktywne usługi głosowe VoIP
1.2 Wymagania w zakresie przepustowości łącza transmisyjnego dla usług fonicznej i transmisji obrazu //-> metody kompresji fonii i obrazu (MP3, MPEG, ),.
//94
Ogólne właściwości standardu MPEG-2
//
Standard MPEG-2 jest pierwszym standardem cyfrowym, opracowanym pod kątem zastosowania w telewizji programowej. Określono w nim metodę kompresji i kodowania sygnału wizyjnego, fonii
oraz danych dodatkowych.
W standardzie tym można transmitować zarówno obrazy wytwarzane w standardzie europejskim
625 linii/50 Hz, jak i w amerykańskim 525 linii/60 Hz. Dopuszczalne są również różne formaty
obrazu, w tym 4:3 i 16:9; wybieranie może być międzyliniowe lub kolejno-liniowe.
//
Metody kodowania w standardach MPEG należą do metod nieodwracalnych, tzn. takich, w których
część informacji nieistotnych w odtwarzanym obrazie jest bezpowrotnie tracona. Przy kompresji
sygnału są wykorzystywane:
korelacja przestrzenna (wewnątrz-obrazowa),
korelacja czasowa,
właściwości wzroku człowieka,
właściwości statystyczne programu.
Metoda kompresji jest oparta na kodowaniu hybrydowym, którego podstawą jest wewnątrz-polowa
transformacja kosinus-owa (DCT) oraz między-polowe kodowanie z prognozowaniem i kompensacją ruchu. W podlegającym kompresji sygnale analogowym, dzięki wykorzystaniu właściwości wzroku człowieka, stosuje się ponad dwukrotne ograniczenie pasma chrominancji w stosunku do pasma luminancji. Korelację przestrzenną (wewnątrz-obrazową) wykorzystuje się dzięki zastosowaniu dyskretnej transformacji kosinus-owej DCT (Discrete Cosine Transform).
Dyskretna transformacja kosinus-owa jest linearną transformacją dwuwymiarową. Ma następujące
zalety:
wykorzystywanie w bardzo dużym stopniu korelacji między elementami obrazu,
zgrupowanie współczynników o znaczących amplitudach w ograniczonej części transformowanej płaszczyzny,
transformacja rzeczywista z podstawowymi funkcjami sinusoidalnymi,
proces odrzucania współczynników lub modyfikacji i kwantowania ich amplitud bardzo podobny do procesu .filtracji linearnej w obecności szumu.
W dyskretnej transformacji kosinus-owej (DCT) przesyłany obraz jest dzielony na małe pod-obrazy
o wymiarach 8×8 elementów, zależnie od zastosowania. Elementy każdego pod-obrazu są próbkowane i przesyłane do kodera dyskretnej transformacji kosinus-owej. Transformacja jest przeprowadzana dla każdego elementu indywidualnie, a więc pod-obraz 8×8 próbek jest przetransformowany na blok 8×8 współczynników (transformant(?)), które reprezentują oryginalny pod-obraz w dziedzinie częstotliwości. Proces transformacji powoduje zgromadzenie większości informacji z obrazu oryginalnego w jednym współczynniku transformacji kosinus-owej. Poziom tego współczynnika jest duży, natomiast poziomy pozostałych są małe.
Dla większości transformowanych pod-obrazów tylko niewielka część współczynników jest znacząco różna od zera, a jedynie te współczynniki muszą być kodowane i przesyłane. W typowych obrazach, amplitudy współczynników dotyczących wyższych częstotliwości przestrzennych są
zwykle bliskie zeru. Liczba ich, podobnie jak liczba znaczących współczynników, zależy od treści
pod-obrazów. Po kwantowaniu współczynniki są grupowane w strumień danych. Stosuje się wówczas specjalne metody wyboru współczynników, zwane metodami klasyfikacji pod-obrazów (blok classification), polegające na wybieraniu współczynników wzdłuż linii ukośnych, tzw. zigzag scanning.
Wykorzystując właściwości statystyczne sygnału, współczynniki dyskretnej transformacji kosinus-owej są kodowane ze zmienną długością słowa. Ogólna zasada kodowania o zmiennej długości słowa (VLC) polega na przypisaniu każdemu symbolowi słowa kodowanego liczby bitów odwrotnie proporcjonalnej do prawdopodobieństwa jego występowania.
W korelacji czasowej sygnału wykorzystuje się zasadę prognozowania z kompensacją ruchu, która
polega na oszacowaniu ruchu różnych obiektów, między polami (lub między kolejnymi obrazami)
i tworzenia prognozy kierunku ruchu. Podstawowym elementem tej metody jest sposób oszacowania przemieszczania się elementów (ruchu). Oszacowanie to jest najczęściej oparte na informacjach kodowanych poprzednio.
Stosowana metoda, tzw. dopasowywanie bloków, polega na określeniu zależności między ruchomymi częściami obrazu i obrazu nadawanego poprzednio. Obraz jest podzielony na bloki, a kompresję ruchu przeprowadza się dwuetapowo. W pierwszym etapie następuje oszacowanie ruchu, tj. przeszukiwanie poprzednio nadawanego obrazu, znalezienie bloku odpowiadającego danemu blokowi i wykonanie ortogonalnego rzutu analizowanego bloku na ten obraz. W drugim etapie jest przeprowadzana kompensacja ruchu, tj. obliczenie wektora przemieszczenia analizowanego bloku (między poprzednim jego położeniem i jego rzutem ortogonalnym) oraz wykorzystanie go do tworzenia prognozy. Metoda ta wymaga przesyłania informacji o wektorze przemieszczenia dla każdego bloku, powoduje więc zwiększenie szybkości przesyłanego sygnału. Nie jest natomiast konieczne przeprowadzenie w dekoderze dodatkowych obliczeń kompensacji ruchu.
W standardzie MPEG-2 obrazy są połączone w grupy o ustalonej strukturze dla całej sekwencji.
Grupy zawierają określoną liczbę obrazów. Dopuszczalne są trzy sposoby kodowania sygnałów
poszczególnych obrazów w grupie:
obrazy typu I (kodowane wewnątrz-obrazowo), w których prognozę tworzy się tylko z informacji w nich zawartych, tj. położonych na tych samych lub sąsiednich liniach wybierania;
obrazy typu P (kodowane z prognozowaniem między-obrazowym), w których prognozę tworzy się z informacji zawartych we wcześniejszym obrazie i informacji o przemieszczeniu elementów danego obrazu w stosunku do elementów wcześniejszego obrazu (wektorze ruchu);
obrazy typu B (kodowane z prognozowaniem dwukierunkowym) w których prognozę tworzy się podobnie jak w przypadku obrazów typu P, ale odniesieniem dla nich są dwa obrazy (wcześniejszy i późniejszy), zapewniające największy stopień kompresji.
Standard nie narzuca struktury sygnału wizyjnego; liczba obrazów poszczególnych typów w grupie
obrazów zależy od konkretnej realizacji kodera.
Standard MPEG-2 może być wykorzystywany do kodowania obrazów o różnej rozdzielczości z zastosowaniem różnych wariantów kompresji sygnałów. W tym celu wprowadzono dwa podstawowe pojęcia: poziom (level) oraz profil (profile).
Poziom jest związany z algorytmami wybierania; przyjęto następujące określenia:
dla telewizji o dużej rozdzielczości obrazu i 1920 próbek na linii, tzw. poziom wysoki 1920;
dla telewizji o dużej rozdzielczości obrazu i 1440 próbek na linii, tzw. poziom wysoki 1440;
liczba linii czynnych dla obu tych poziomów wynosi 1152;
dla telewizji konwencjonalnej, tzw. poziom główny o rozdzielczości 720 punktów × 576 linii, który może być również wykorzystywany w systemach o poprawionej jakości
(o rozszerzonym formacie obrazu);
dla telewizji o małej rozdzielczości obrazu (352 punkty × 288 linii), tzw. poziom niski.
Sygnałami wejściowymi są zawsze sygnały składowe telewizji kolorowej.
W każdym z tych poziomów można stosować różne metody kompresji sygnału, aby uzyskać różne
szybkości przesyłania. Parametry te nazwano profilem.
W standardzie przyjęto pięć podstawowych profili:
profil prosty,
profil główny,
profil skalowany szum-owo (SNR scalable),
profil skalowany przestrzennie,
profil wysoki.
Szybkość bitowa przesyłanego sygnału zależy od kombinacji poziom/profil i wynosi dla telewizji
konwencjonalnej (SDTV) 2 ÷ 4 Mbit/s, a dla telewizji dużej rozdzielności (HDTV) 8 ÷ 10 Mbit/s.
Potwierdzona wynikami badań szybkość, przy transmisjach eksperymentalnych sygnałów SDTV,
kodowanych według standardu MPEG-2, przy jakości odtwarzanego obrazu równorzędnej jakości
obrazu analogowego, wynosi średnio 3,5 Mbit/s.
Minimalne szybkości bitowe dla standardu MPEG-2 oraz jakości SDTV zależą od treści przesyłanego obrazu i wynoszą około 3,5 Mbit/s, natomiast dla obrazów krytycznych (o dużej zawartości ruchu) do 4,5 Mbit/s.
Ogólne właściwości standardu MPEG-4 i H.264/AVC
Szeroko stosowany w praktyce MPEG-2 został ulepszony w 1991 r. przez grupę MPEG i nazwany standardem MPEG-4, zgodnym z normą ISO/IEC. Standard ten wykorzystuje bardziej zaawansowane techniki kompresji oraz wiele dodatkowych narzędzi, umożliwiających kodowanie i manipulowanie mediami cyfrowymi. Rozwiązania te są oparte na znanym modelu kodowania hybrydowego DPCM/OCT, a podstawowe funkcje modelu są wspomagane, np. zwiększeniem wydajności kompresji, niezawodności transmisji, kodowaniem niezależnych obiektów sceny wizyjnej, kompresją opartą na siatce oraz ożywianiem twarzy i modeli ludzkich. Jest to standard bardzo skomplikowany o równie skomplikowanym oprogramowaniu. Oczywiście nie każde zastosowanie wymaga użycia wszystkich możliwości standardu. W standardzie MPEG-4 opisano wiele profili grupujących narzędzia dla poszczególnych zastosowań, między innymi: wydajne kodowanie ramek wizyjnych, kodowanie wizyjne dla zawodnych sieci transmisyjnych, kodowanie i manipulację oparte na obiekcie, kodowanie syntetycznych, hybrydowych i syntetyczno-naturalnych scen oraz interaktywne zastosowania wizyjne. Jednak z punktu widzenia zastosowań, najbardziej są potrzebne narzędzia profilu kodowania prostego i ulepszonego prostego oraz wydajnego kodowania prostokątnych ramek. Wymagania takie spełnia standard H.264/AVC, opracowany w 2003 r. w celu zastąpienia standardu MPEG-4, opublikowany w normie ISO/IEC 14496-10 i zaleceniu ITU-T H.264 (03/2005).
Podobnie jak koder standardu MPEG-2, koder standardu H.264/AVC jest koderem hybrydowym z kompensacją ruchu.
W standardzie H.264/AVC wprowadzono pewne innowacje dotyczące sposobu kodowania obrazów
w sekwencji wizyjnej, a mianowicie:
każdy obraz w sekwencji może być zakodowany niezależnie jako ramka (frame), pola (fields) oraz w trybie adaptacyjnym MBAFF;
może być więcej niż jeden obraz odniesienia zarówno na liście odniesienia wstecz, jak i w przód;
obrazy mogą być kodowane praktycznie w dowolnej kolejności.
Wartości próbek obrazu i wektory ruchu są wyliczane na podstawie prognozy danych zawartych w sąsiadujących blokach 4×4.
Obrazy kodowane w trybie między-obrazowym (P i B) są rekonstruowane przy użyciu jednego lub więcej obrazów odniesienia, występujących w sekwencji wcześniej lub później w stosunku do bieżącego obrazu.
Każdy z makro-bloków może zostać podzielony w procesie kodowania na prostokątne fragmenty o rozmiarach 16 × 8, 8 × 16, 8 × 8, 8 × 4, 4 × 8 oraz 4 × 4 próbki luminancji.
W standardzie H.264/AVC zdefiniowano dwa ogólne schematy prognozy wektorów ruchu: prognozy kierunkowej dla makro-bloków podzielonych na prostokąty o rozmiarze 16 × 8 i 8 × 16 oraz adaptacyjnej prognozy median-owej dla pozostałych przypadków.
W standardzie stosuje się tryby kodowania makro-bloku z pomijaniem całości (SKIP) lub części danych (DIRECT). Tryby kodowania makro-bloków pomijanych SKIP i DIRECT są szczególnymi trybami prognozy z kompensacją ruchu, występującymi w obrazach typu P i B. Dla tych makro-bloków w strumieniu binarnym nie są przesyłane żadne dane (SKIP) lub są przesyłane wyłącznie współczynniki transformaty błędów prognozy (DIRECT).
Standard H.264/AVC jest standardem wizyjnym, natomiast standardy kodowania dźwięku towarzyszącego są takie same, jak dla standardu MPEG-2. Standard ten dotyczy wyłącznie kodowania źródłowego, jest przesyłany za pomocą strumienia transportowego MPEG-2 TS, podobnie jak w MPEG-2.
Zasadnicze różnice między MPEG-2 a H.264/AVC
Poniżej wymieniono podstawowe różnice między standardem MPEG-2 a standardem H.264/AVC:
adaptacyjny podział makro-bloków od 16 × 16 do 4 × 4 próbek luminancji na blok;
kodowanie adaptacyjne sekwencji wizyjnych – na poziomie obrazu (PAFF) oraz na poziomie makro-bloków (MBAFF);
specjalne tryby rekonstrukcji makro-bloków z pomijaniem danych (SKIP i DIRECT);
zaawansowanie prognozowania wewnątrz-obrazowego;
zaawansowanie prognozowania między-obrazowego z większą niż jeden liczbą obrazów odniesienia;
transformata całkowitoliczbowa błędów prognozowania w blokach o wielkości 4 × 4 próbki;
kontekstowe kodowanie entropijne – kodowanie o zmiennej długości (VLC) lub kontekstowym adaptacyjnym koderem adaptacyjnym (CABAC);
transformata całkowitoliczbowa błędów prognozy w blokach o wielkości 4 × 4 próbki;
specjalne tryby rekonstrukcji makro-bloków z pomijaniem danych (SKIP i DIRECT);
zaawansowane narzędzia do kodowania sekwencji wizyjnych z przeplotem (PAFF oraz MBAFF);
wieloobrazowa kompensacja ruchu z wykorzystaniem jako odniesienia poprzednio kodowanych obrazów, znacznie bardzie elastycznie niż w poprzednich standardach, tj. umożliwiających stosowanie 32 obrazów odniesienia oraz wiele innych, bardzo „wyrafinowanych” szczegółów technicznych.
Zakres stosowania standardów
Standard MPEG-2 znalazł zastosowanie w wielu dziedzinach transmisji, przetwarzania i przechowywania treści telewizyjnych, np.:
w telewizji programowej satelitarnej DVB-S, kablowej DVB-C i naziemnej DVB-T;
w telewizji wysokiej rozdzielczości HDTV, w ograniczonym zakresie;
w telewizji płatnej;
w zapisie na nośnikach DVD.
Standard H.264/AVC ma więcej zastosowań, oprócz takich jak MPEG-2, a mianowicie:
w telewizji w telefonii trzeciej generacji;
w technikach militarnych NATO;
w telewizji w mediach strumieniowych;
w telekonferencjach;
w zapisie na nośnikach HD-DVD oraz Blu-ray Disk;
w usługach wideo na życzenie w sieciach internetowych;
w piątej generacji iPod do odtwarzania sekwencji wizyjnych firmy Apple;
w przenośnych stacjach gier Playstation Portale firmy Sony.
Standard ten zastosowano w telewizji naziemnej we Francji, USA, Rosji, Niemczech i Korei Płd. We Francji standard H.264/AVC zastosowano dla telewizji HDTV i w programach płatnych, natomiast w Niemczech i Rosji – dla HDTV.
W Japonii wprowadzono usługę odbioru telewizji w ruchu ISDB-T w sieciach głównych dostawców: NHK, Tokyo Broadcasting System (TBS), Nippon Television (NTV), TV Asahi, Fuji TV oraz TV Tokyo.
Bezpośredni odbiór z satelity zapewniają nadawcy: DirecTV (w USA), Dish Network (w USA), Euro1080 (w Europie), Premiere (w Niemczech), ProSieben HD & Sat1 HD (w Niemczech) oraz BSkyB (w Zjednoczonym Królestwie i Irlandii).
Wnioski
Na podstawie analizy porównawczej opisywanych standardów można sformułować następujące wnioski.
Standard H.264/AVC zapewnia przy takiej samej subiektywnie ocenianej jakości obrazu uzyskanie prędkości bitowej o połowę mniejszej niż standard MPEG-2.
Obydwa standardy wymagają oprogramowania, które przy obecnym stanie techniki jest co kilka lat wymieniane na nowocześniejsze. Biorąc to pod uwagę, standard MPEG-2 staje się już przestrzały.
Kodowanie w obydwu standardach jest nieodwracalne, tzn. informacje stracone w procesie kodowania zostają stracone bezpowrotnie i nie można ich odtworzyć, co ma wpływ na jakość odtwarzanych obrazów.
Standard H.264/AVC wchodzi coraz szerzej do eksploatacji, szczególnie w HDTV i telewizji płatnej.
Sygnały fonii stereofonicznej wymagają przepływności 192 kbit/s, fonia w systemie Dolby Surround 256 kbit/s, a fonia AC3 448 kbi/s.
Podsumowując, można stwierdzić, że:
standard H.264/AVC jest standardem przyszłościowym, znajduje bowiem coraz szersze zastosowanie, natomiast standard MPEG-2 staje się standardem przestarzałym i będzie stopniowo wypierany przez rozwiązania nowocześniejsze, dające znacznie szersze możliwości;
//94
//pdf_NOWOCZESNE_METODY_EMISJI_UCYFROWIONEGO_SYGNA_U_TELEWIZYJNEGO_Bogdan_Uljasz.pdf
NOWOCZESNE METODY EMISJI
UCYFROWIONEGO SYGNAŁU TELEWIZYJNEGO
Wprowadzenie
Tempo rozwoju w technice cyfrowej zaowocowało powstaniem wielu metod cyfryzacji sygnałów fonicznych oraz obrazu nieruchomego i ruchomego. Obecne możliwości technologiczne pozwalają już na rejestrację i odtwarzanie sygnałów cyfrowych za pomocą niewielkich i nieskomplikowanych ze względu na użytkownika urządzeń.
Nowoczesne metody kompresji, modulacji czy zabezpieczenia transmisji przed błędami pozwalają na przesyłanie sygnałów cyfrowych w wolnej przestrzeni z coraz to większą przepływnością w stosunkowo wąskim pasmie częstotliwości. Systemy transmisyjne pozwalają na uzyskanie wysokiej wierności na wyjściu traktu telekomunikacyjnego.
W standardzie MPEG-2 stosowana jest metoda stratna kompresji wizji. Metoda kompresji stosowana w standardzie MPEG-2 wykorzystuje:
korelacje przestrzenna - dyskretna transformata kosinusowa DCT;
korelacje czasowa – różne typy ramek;
właściwości oka ludzkiego;
właściwości statystyczne sygnału - w transmitowanym sygnale pewne symbole pojawiają się częściej, a inne rzadziej.
Etapy kompresji MPEG-2:
redukcja rozdzielczości z 10 do 8 bitów,
pominiecie informacji związanych z wygaszaniem linii i pola,
redukcja rozdzielczości kolorów (4:2:0),
kwantyzacja za pomocą różnicowej modulacji PCM (DPCM),
zastosowanie dyskretnej transformaty cosinusoidowej ze współczynnikami,
zastosowanie kodowania Zig-Zag z kodowaniem o zmiennej długości,
zastosowanie kodowanie Huffmana.
W standardzie MPEG-2 cała sekwencja podzielona jest na grupy obrazów GOP - rys. 2.
Rysunek 2. Przykładowa struktura grupy obrazów GOP [1]
Długość i postać GOP nie jest określona i może być zmienna w czasie transmisji obrazu. GOP składa się z trzech typów ramek obrazu.
Przy kompresji ramki typu I (ang. Intra Frame) wykorzystywana jest korelacja przestrzenna. Ramki I są to tzw. ramki referencyjne. Ramki I są kodowane niezależnie od reszty danych wideo i zawierają informacje pełną o obrazie.
Ramki typu P (ang. Predicted Frame) są komprymowane przy użyciu jednokierunkowej kompensacji ruchu. Kodowanie ich przebiega na podstawie predykcji z ostatniej ramki I bądź P (tej, która była bliższa). Ramki P związane są z chwilami kwantyzacji DPCM pomiędzy ramkami referencyjnymi.
Ramki typu B (ang. Bidirectional Predicted Frame) komprymowane są przy użyciu dwukierunkowej kompensacji ruchu. Ramki typów I i P to tzw. ramki kotwiczne dla ramek B. Ramki B kodowane są na podstawie predykcji z poprzedniej i następnej ramki kotwicznej.
Rysunek 3 Koder ramki typu I [1]
Rysunek 4 Koder ramki typu P [1]
[1] http://oceanic.wsisiz.edu.pl/~waskowie/telewizja_cyfrowa.htm
Poszczególne typy ramek stosowane w standardzie MPEG-2 zapewniają różne stopnie kompresji. Obrazy typu I zawierają pełna informacje o obrazie. Obrazy typu B i P zawierają jedynie informacje o zmianach występujących względem obrazów odniesienia.
System przesyłowy sygnału cyfrowego
W koderze standardu MPEG-2 skompresowane sygnały wizji, fonii i dodatkowych danych (np. teletekstu) są łączone w jeden sygnał cyfrowy. Na wyjściu kodera wizji i fonii znajdują się układy, które dzielą strumienie danych na pakiety elementarne PES (ang. Packetized Elementary Streams). Podział na pakiety elementarne PES może być dokonany w sposób prawie dowolny. Jedynym ograniczeniem jest maksymalna długość pakietu wynoszącą 64 kB. Pakiet PES jest rozpoznawany na podstawie nagłówka, który zawiera:
3-bajtową sekwencję startową (00 00 01 hex),
1-bajtowy identyfikator strumienia, do którego należy pakiet, liczba identyfikatorów strumieni została ograniczona do 32 dla fonii i 16 dla wizji; dzięki temu zagwarantowane jest, że w strumieniu danych nie powtórzy się sekwencja identyfikatora strumienia,
2 bajty określające długość pakietu (stąd ograniczenie długości pakietu do 64 kB),
2 bajty flag sygnalizujących występowanie w nagłówku pól dodatkowych, z których najważniejsze są: znacznik czasu prezentacji PTS (ang. Presentation Time Stamp) i znacznik czasu dekodowania DTS (ang. Decoding Time Stamp). Pola te są wykorzystywane do synchronizacji dekodowania poszczególnych strumieni danych,
1 bajt określający długość nagłówka,
pola dodatkowe, jeśli zostało to zaznaczone w bajtach nagłówków.
Bezpośrednio po nagłówku znajdują się dane przesyłane w tym pakiecie. Standard MPEG-2 przewiduje stosowanie dwóch rodzajów multiplekserów: programowego (ang. Program Multiplexer) i transportowego (ang. Transport Multiplekser).
W pierwszym przypadku sygnał wyjściowy kodera - strumień programowy (ang. Program Stream) jest tworzony przez zwykłe przeplatanie elementarnych pakietów danych należących do jednego programu telewizyjnego
Strumień transportowy (ang. Transport Stream) tworzony jest tak, że elementarne pakiety danych PES są dzielone na mniejsze pakiety o stałej długości równej 184 bajty, przy czym w strumieniu transportowym mogą być umieszczane elementarne pakiety danych pochodzące z różnych programów telewizyjnych. Sposób podziału na pakiety strumienia transportowego jest ścisłe określony.
Dekodowanie strumienia transportowego MPEG-2 rozpoczyna się od wydzielenia z całego strumienia tablicy PAT. Na jej podstawie dekoder określa numery pakietów składające się na program, który ma być w tej chwili odbierany. Następnie ze strumienia transportowego wybiera tylko pakiety o odpowiednich numerach, pomijając wszystkie należące do innych programów. Pakiety odpowiadające poszczególnym strumieniom, z których składa się dobierany program, są grupowane w odpowiedniej kolejności, tak aby odtworzyć elementarne pakiety danych PES.
[3] Norma ISO/IEC 13818-1:2000
//pdf_NOWOCZESNE_METODY_EMISJI_UCYFROWIONEGO_SYGNA_U_TELEWIZYJNEGO_Bogdan_Uljasz.pdf
//473
//TV
3. Analiza porównawcza algorytmów kompresji sygnałów z punktu widzenia wymaganej prędkości bitowej i jakości odtwarzanego obrazu
Jak wynika z podanych powyżej rozważań pełna cyfryzacja telewizji naziemnej w Polsce jest nieunikniona. Pociąga to za sobą konieczność zapewnienia odbiorcom obrazu telewizyjnego wysokiej jakości. Jednocześnie tendencje światowe i rozwój przemysłu, a więc coraz powszechniejsza dostępność szerokoekranowych odbiorników telewizyjnych LCD pociąga za sobą powszechne nadawanie telewizji HDTV, której emisja jest wyłącznie cyfrowa. Powstała więc konieczność ustalenia podstawowych parametrów transmisyjnych systemu cyfrowego, zapewniających jak najwyższą jakość odtwarzanych obrazów przy optymalnym wykorzystaniu przydzielonego widma częstotliwości.
Podstawowy system transmisyjny do emisji naziemnej telewizji cyfrowej został określony przez normę ETSI EN 300 744, której ostatnia wersja została zatwierdzona w roku 2004, a obecnie dyskutowany jest projekt z września 2008, który powinien z godnie z planem być przyjęty w styczniu 2009 (polskie tłumaczenie dotyczy wersji z r 2001[3]). W normie tej opisano funkcjonalny blok urządzeń wykonujących adaptacje sygnałów telewizyjnych w paśmie podstawowym przychodzących z wyjścia multipleksera transportowego do parametrów kanału naziemnego, obejmującą randomizację, kodowanie zewnętrzne i wewnętrzne, przeplatanie, modulację i multipleksowanie z ortogonalnym podziałem częstotliwości. Sygnałami wejściowymi na system są kodowane sygnały wizyjne kilku programów telewizyjnych z wyjścia multipleksera. Podstawowe parametry tych sygnałów mają znaczny wpływ na jakość odtwarzanych obrazów oraz liczbę i rodzaj sygnałów w multipleksie. Dlatego są one analizowane i badane w celu ustalenia ich optymalnych wartości. Należą do nich przede wszystkim algorytmy kodowania, wymagana prędkość bitowa sygnału oraz rodzaj strumienia transportowego.
3.1. Algorytmy kodowania sygnałów wizyjnych
W chwili obecnej przy transmisji sygnałów DVB-T są stosowane dwa standardy kodowania sygnału wizyjnego: MPEG2 i tzw. MPEG4 ( AVC/H264) Określają one metody kompresji i kodowania sygnału wizyjnego, fonii i danych dodatkowych. Obydwa standardy należą do metod nieodwracalnych tzn. takich, w których część informacji nieistotnych w odtwarzanym obrazie jest bezpowrotnie tracona w procesie kodowania. Metody kompresji stosowane w standardach wykorzystują: korelację przestrzenną (kodowanie transformacyjne), korelację czasową (prognozowanie z kompensacją ruchu), właściwości ludzkiego oka, właściwości statystyczne programu (kodowanie ze zmienną długością słowa) Opracowany w 1993 roku [4] standard MPEG 2 umożliwia zarówno transmisję obrazów wytwarzanych w standardzie europejskim 625 linii/50 Hz jak i amerykańskim 525 linii/60 Hz, dopuszczalne są w nim również różne formaty obrazu w tym 4:3 i 16:9, wybieranie może być międzyliniowe lub kolejno liniowe. Może on być wykorzystywany dla kodowania obrazów o różnej rozdzielczości przy zastosowaniu różnych wariantów kompresji sygnałów. Standard MPEG 2 był w okresie ostatnich 15-tu lat powszechnie stosowany w krajach, które rozpoczynały emisję naziemną sygnałów telewizyjnych i jest w nich nadal stosowany. W Polsce pierwsze emisje eksperymentalne naziemnej telewizji cyfrowej DVB-T były prowadzone również w standardzie kodowania MPEG2.
Standard AVC/H264 jest naturalnym sukcesorem cieszącego się dużym powodzeniem standardu MPEG 2. Po ponad 10-cio letniej eksploatacji technologii MPEG 2 powstało zainteresowanie nowymi technologiami zapewniającymi większą wydajność kodowania niż technologie eksploatowane. Wynikło to zarówno z potrzeb producentów programów dążących do wytwarzania obrazów o coraz większej rozdzielczości z HDTV włącznie, zapewniających większą wierność obrazów niż telewizja standardowa. . Jednocześnie nadawcy poszukiwali możliwości umieszczenia w dostępnym paśmie częstotliwości większej liczby kanałów. Powstała więc konieczność opracowania kodeków o większej skuteczności kompresji. W roku 2003 został opracowany standard AVC/H264. Standard ten wykorzystuje bardziej zaawansowane techniki kompresji oraz wiele dodatkowych narzędzi umożliwiających kodowanie i manipulowanie mediami cyfrowymi, jak adaptacyjny podział makrobloków do 4x4 próbek luminancji i specjalne tryby ich rekonstrukcji, kodowanie adaptacyjne sekwencji wizyjnych, zaawansowane prognozowanie wewnątrz i między obrazowe i wielo obrazowa kompensacja ruchu. Standard AVC/H264 znalazł szerokie zastosowanie zarówno w emisji sygnałów telewizyjnych w tym telewizji o dużej rozdzielczości obrazu (HDTV), lecz również w wielu dziedzinach transmisji, przetwarzania i przechowywania treści wizyjnych. Prowadzone obecnie w Polsce emisje eksperymentalne naziemnej telewizji cyfrowej DVB-T są prowadzone wyłącznie w standardzie kodowania AVC/H264. Dzięki zastosowaniu bardziej zaawansowanych technik kompresji standard AVC/H264 zapewnia przy takiej samej ocenianej subiektywnie jakości obrazu uzyskanie dla jednego programu telewizyjnego prędkości bitowej o połowę mniejszej niż standard MPEG 2.(patrz rozdział 3.2.). Jest on obecnie powszechnie stosowany w szerokim zakresie usług telewizyjnych od urządzeń ruchomych o prędkościach bitowych poniżej 30 kb/s, poprzez telewizję internetową, telewizję o standardowej rozdzielczości (SDTV) do telewizji dużej rozdzielczości obrazu (HDTV).
3.2. Wymagana prędkość bitowa
Zapewnienie emisji telewizyjnych sygnałów cyfrowych o określonej dla danej służby jakości i rozdzielczości wymaga przesłania odpowiedniej liczby bitów, a więc odpowiedniej prędkości bitowej. Prędkość ta zależy od przyjętego algorytmu kodowania. Prędkość bitowa dla transmisji sygnałów wizyjnych SDTV została określona przede wszystkim na podstawie analiz i badań zależności jakości obrazu od prędkości bitowej sygnału. Przeprowadzone w Instytucie Łączności w roku 1993 badania eksperymentalne wykazały, ze prędkość bitowa sygnałów SDTV kodowanych wg. standardu MPEG 2 przy jakości odtwarzania obrazu równorzędnej jakości obrazu analogowego wynosi około 3,5 Mb/s, przy czym zależy ona w dużym stopniu od treści przesyłanego obrazu i dla obrazów o treści krytycznej (dużej zawartości ruchu) wzrasta do 4,5 Mb/s. W roku 1993 przeprowadzono w laboratoriach w Niemczech, Włoszech, Japonii i USA [5] eksperymentalne subiektywne badania porównawcze jakości odtwarzanych obrazów kodowanych według standardów MPEG 2 I AVC/H264. Sygnałami wejściowymi były znormalizowane sekwencje pomiarowe zawierające obrazy o różnej krytyczności i różnej zawartości ruchu. Pomiary wykazały znaczna przewagę standardu AVC/H264 nad standardem MPEG 2 dla wszystkich ustawień pomiarowych. Dla sekwencji kodowanych według standardu AVC/H264 zauważono znacznie mniejsze zniekształcenia kolorów ( w szczególności nasyconych), mniejsze zniekształcenia o charakterze szumu oraz brak efektów kodowania bloków niż dla sekwencji kodowanych według standardu MPEG 2. W przypadku kodowania AVC/H264 obrazów SD o małej zawartości ruchu („mobile” i „tempete”) taką samą jakość odtwarzanego obrazu jak dla kodowania MPEG 2 uzyskano się przy prędkości bitowej o połowie mniejszej. Dla tych dwóch obrazów bardzo dobrą jakość obrazów SD zapewnia przesłanie już 1,5 Mb/s, podczas gdy dla przesłania obrazu ”mobile” o takiej samej jakości kodowanego wg. standardu MPEG 2 niezbędne jest przesłanie strumienia 6Mb/s. Natomiast dla obrazów zawierających dużo ruchu i dużo szczegółów jak „Husky” i „Football” akceptowana jakość obrazów kodowanych AVC/H264 uzyskuje się 2.25 Mb/s, co jest zupełnie nieosiągalne w przypadku kodowania MPEG 2. W przypadku sygnałów HD („Crew” i ‘”Riverbed”) kodowanych według standardu AVC/H264 prędkość ta wynosiła 6 Mb/s. Odpowiednia prędkość bitowa sygnałów w przypadku kodowania MPEG 2 wynosiła 10 Mb/s. Przeprowadzona w Instytucie Łączności w 2005 [1] teoretyczna analiza porównawcza powyższych standardów kodowania potwierdziła tę opinię. Określenie wymaganych prędkości bitowych dla poszczególnych programów umożliwia określenie budowy poszczególnych multipleksów. Przy rozważaniu zawartości multipleksu należy przy tym uwzględnić, że oprócz programów wizyjnych należy w multipleksie przesłać sygnały fonii towarzyszącej i danych: na przykład fonii towarzyszącej AC 3 o prędkości 448kb/s, teletekstu o prędkości średnio 200 kb/s, sygnały EPG około 500 kb/s oraz inne usługi dodane o prędkości do 1 Mb/s.
3.3. Budowa strumienia transportowego
Transmisja zakodowanych sygnałów wizji, fonii i danych następuje za pomocą strumienia transportowego. Obecnie w telewizji cyfrowej naziemnej, kablowej i satelitarnej (z wyjątkiem standardu satelitarnego DVB-S2) jest stosowany powszechnie ,niezależnie od standardu kodowania, strumień transportowy MPEG 2-TS. Strumień ten zawiera połączone i zmultipleksowane elementarne strumienie transportowe poszczególnych programów z dźwiękiem towarzyszącym oraz danymi. Budowa strumienia jest ściśle określona, a jego wielkość ograniczona jedynie możliwościami medium transmisyjnego (szerokość pasma częstotliwości, prędkość bitowa).
Inną filozofię transmisji programów telewizyjnych „na żywo” lub „na żądanie” wykorzystuje telewizja internetowa, bazująca na transmisji strumieniowej z wykorzystaniem protokółu IP czyli przesyłaniu pakietów utworzonych na bazie strumienia transportowego.
3.4. Kodowanie dźwięku towarzyszącego
Standard kodowania dźwięku towarzyszącego obrazowi nie budzi większych kontrowersji w środowisku technicznym. Grupa DVB dotychczas nie określiła jaki standard kodowania dźwięku przewiduje w następnej generacji nadawania. Spośród możliwych standardów kodowania dźwięku, a mianowicie MP2 multi (MPEG2 layer 2 multicannel), AC 3 (Dolby Digital), E-AC-3 (Dolby Digital Plus) MPEG4 AAC Level 4, MPEG 4 HE AAC Level 4 powszechnie jest stosowany, oraz przewidywany do zastosowania w przyszłości standard E-AC-3 (Dolby Digital Plus).
//473
//straty -> (fe) (BER) ?? 1.3 Właściwości usługi wideokonferencyjnej - multimedialnej //Definicja usług wideotelefonii i wideokonferencji
Definicja usług wideotelefonii i wideokonferencji
Na podstawie opracowania "MODEL KOMUNIKACJI MULTIMEDIALNEJ H.320, H.323." Bożeny Erdmann
Usługa wideotelefonii to audiowizualna teleusługa konwersacyjna, zapewniająca dwukierunkowy, symetryczny przekaz sygnału głosu i kolorowego obrazu ruchomego pomiędzy dwoma lokalizacjami (użytkownik - do - użytkownika) w czasie rzeczywistym, poprzez leżące pomiędzy nimi sieci. Wymagania minimalne zakładają, że w warunkach normalnych transmitowana informacja wideo jest wystarczająca do odpowiedniego odwzorowania płynnych ruchów osoby, w ujęciu przedstawiającym głowę i ramiona.
Usługa wideokonferencji zapewnia dwukierunkowy przepływ sygnału głosu i kolorowego obrazu ruchomego pomiędzy grupami użytkowników w dwu lub więcej oddzielnych lokalizacjach. Wymagania minimalne zakładają, że w warunkach normalnych transmitowana informacja wideo jest wystarczająca do odpowiedniego odwzorowania płynnych ruchów dwóch lub więcej osób w sytuacji typowej dla posiedzenia, w ujęciu przedstawiającym głowę i ramiona.
Funkcje przewidziane definicją - uzupełnione o niezbędną sygnalizację i sterowanie - mogą, ale nie muszą być rozszerzone na dalsze usługi transmisyjne: transmisję obrazów nieruchomych wysokiej rozdzielczości, dokumentów, zdjęć, tabel itd. Rozróżnia się dwa rodzaje usług wideotelefonicznych: w sieciach wąsko - i szerokopasmowych, przy czym główna różnica tkwi w rozdzielczości przestrzennej i czasowej przekazywanych obrazów (dla sieci szerokopasmowych o jakości zbliżonej do standardowej jakości telewizyjnej), jakości dźwięku (w sieciach szerokopasmowych w miarę możliwości stereo) oraz opcjonalnym / standardowym wyposażeniu w urządzenia do transmisji innych sygnałów (łącznie z filmami, instruktażami oraz obrazami 3D). Rozważa się również możliwości dostępu do poczty elektronicznej za pośrednictwem terminala wideotelefonicznego. Zakłada się również, że powinna istnieć możliwość wyboru prędkości transmisji dla sygnału głosowego, zwłaszcza, gdy może mieć to wpływ na opłaty lub jakość transmisji wideo.
Celem realizacji funkcji podstawowych terminal wyposażony musi być w urządzenia realizujące: odbiór i prezentację obrazu oraz głosu drugiej strony, kodowanie audio i wideo oraz zarządzanie interfejsem sieciowym (dla połączeń wideotelefonicznych wielopunktowych wymagane być mogą dodatkowe funkcje) możliwe rozszerzenia wyposażenia terminala wideotelefonicznego: ruchoma kamera i powiększenie (zoom), interfejsy dla dodatkowej kamery, ekrany, zapis wideo, zdalne sterowanie zdalną kamerą, klawiatura dla usług tekstowych. Najważniejszym zadaniem jest, aby terminal wideotelefoniczny spełniał wszystkie funkcje zwykłego telefonu. Musi istnieć możliwość połączenia się ze zwykłym telefonem (procedury fall back(?)) o szerokości pasma analogowego 3.1 kHz, 7 kHz lub wideotelefonem w innej sieci lub innego producenta, z dodatkowym zagwarantowaniem krótkiego czasu zestawiania połączenia. Wideoterminal musi mieć zaimplementowane procedury kodowania G.711 (jest to wymaganie minimalne): PCM według prawa mi oraz A(?).
Dodatkowo powinna istnieć możliwość dwuetapowego zestawiania połączenia wideotelefonicznego: pierwsza faza obejmuje zastawianie połączenia głosowego, zaś po jego utworzeniu, na życzenie użytkowników, dodać można kanał wideo. Jeśli cała wymagana dla takiej transmisji przepływność nie jest dostępna, rozmowa powinna być kontynuowana, z maksymalną osiągalną jakością transmisji sygnału wideo. Musi istnieć możliwość - tak dla strony wywołującej, jak i wywoływanej - wyłączenia wychodzącego sygnału wideo bez przerywania istniejącego połączenia; przewidziany być powinien na tę okoliczność obraz zastępczy. Zakłada się istnienie opcji prezentacji użytkownika na własnym terminalu (self – view), aktywowanej przed lub w trakcie połączenia.
Ważną zaletą jest możliwość użycia wideotelefonii w komunikacji osób z upośledzeniem organów mowy lub słuchu, posługujących się np. językiem migowym. Z tego względu informacja o kolejnych etapach zestawiania połączenia powinna być, oprócz standardowej sygnalizacji dźwiękowej, wyświetlana na ekranie w formie napisów lub obrazów; ewentualnie również z prezentacją procesów po stronie wywoływanej.
Wymagana jest synchronizacja dźwięku z obrazem (brak dostrzegalnych opóźnień). Należy uwzględnić całkowite opóźnienie wprowadzane przez kodeki oraz urządzenia transmisyjne.
Możliwe są następujące konfiguracje połączenia wideotelefonicznego:
konfiguracja punkt - punkt (zapewniana bezpośrednio przez sieć transmisyjną, nie wymagająca pośrednictwa dodatkowych, specjalizowanych urządzeń);
konfiguracja wielopunktowa - wymagająca zastosowania mostka konferencyjnego MCU (szczególnym przypadkiem wideokonferencji jest też wideokonferencja pomiędzy dwoma terminalami).
Wideokonferencja w sieci wąskopasmowej traktowana jest jako oddzielna teleusługa, nie zaś usługa dodatkowa w ramach wideotelefonii.
Wideokonferencja
Wyróżnia się dwa rodzaje usług wideokonferencyjnych:
podstawowe usługi wideokonferencyjne (VCS - Basic Videoconference Services), oferowane standardowo w cyfrowych systemach teletransmisyjnych o przepływnościach rzędu p 64 kbit/s (p z zakresu 2 do 30, czyli od ISDN do PCM 30/32); tylko w trybie bez prowadzenia (z użyciem funkcji podziału ekranu - splitscreen lub aktywacji głosowej);
usługi wideokonferencyjne podwyższonej jakości (jakość jak dla standardowej telewizji, wymaga sieci szerokopasmowych).
Wideokonferencje o połączeniach punkt - punkt zapewniają zawsze dwukierunkową, symetryczną transmisję sygnałów audio i wideo. W przypadku wideokonferencji wielopunktowej, transfer dwukierunkowy symetryczny zapewniony jest pomiędzy każdym z terminali a mostkiem wideokonferencyjnym MCU.
Wśród wideokonferencji wielopunktowych można dalej rozróżnić:
wideokonferencję wielokanałową (każda strona połączona jest z każdą kanałem wideo, prezentowanym na podzielonym ekranie; MCU odpowiada tylko za miksowanie sygnałów audio i zarządzanie konferencją. Ilość dostępnych danej lokalizacji kanałów ogranicza liczbę uczestników wideokonferencji);
wideokonferencję z kanałem dzielonym (zawsze wymaga MCU, odbierających sygnały wideo od wszystkich stron i obrabiający je przed rozesłaniem),
wideokonferencję komutowaną (wymaga minimum jednego MCU, który odbiera sygnały od wszystkich lokalizacji, wybiera sygnał do przesłania każdemu z użytkowników według predefiniowanych zasad, dołączając zbiorczy sygnał audio).
W ramach podstawowych usług wideokonferencyjnych, wymagających przepływności n(?) 384 kbit/s transmitowany jest standardowo (w większości terminali uwzględniono tę dodatkową obok 3.1 kHz opcję) sygnał audio o analogowej szerokości pasma 7kHz, więc postrzegana subiektywnie jakość nie różni się od oferowanej przez rozszerzone usługi wideokonferencyjne.
Opcje dodatkowe dla usługi wideokonferencji obejmują: podział ekranu, transmisję faksową, szyfrowanie danych, przewodniczenie wideokonferencji (dla połączeń wielopunktowych), identyfikację rozmówcy. Dodatkowe wyposażenie terminala wideotelefonicznego dla celów wideokonferencji obejmować może: kilka mikrofonów, sterowanych głosem lub ręcznie; kamera realizująca różne ujęcia, identyfikacja wyświetlanej na ekranie strony, panel do sterowania konferencją. Przewiduje się też możliwość wykorzystania usługi wideokonferencji do innych (niż biznesowe) zastosowań, jak np. transmisji sygnałów rozsiewczych TV, telenauczania, dyskusji panelowych itd.
Konferencje mogą być realizowane: na żądanie, na bazie stałego lub półstałego (rezerwowanego) łącza.
Zasady, które ujednolicić należy, aby prowadzić można było wideokonferencje pomiędzy różnymi operatorami:
podstawowe warunki rezerwacji (okresy rezerwacji, rejestracji, kasowanie rezerwacji, rozszerzenie rezerwacji);
informacje niezbędne do dokonania rezerwacji (data, lokalizacje terminali, nazwiska użytkowników, parametry techniczne);
zestawianie połączenia i konferencji;
rozłączanie; kończenie rozmowy; przedłużenie rozmowy;
procedury postępowania w przypadku błędów;
zaliczanie, billing;
zmiana trybu wideokonferencji itd.
Wyróżnia się rozmaite tryby konferencji wielopunktowej, ze względu na przydział ekranu dla poszczególnych stron uczestniczących w połączeniu i funkcje sterowania prezentowanym obrazem:
Tryb bez prowadzenia (wszystkie strony równouprawnione):
przełączanie głosem (Voice switching) najdonośniejsza strona połączenia, wykrywana automatycznie przez MCU prezentowana jest na wizji (również z automatycznym sterowaniem detektorem ciszy);
tryb obrazu dzielonego z opcją współpracy (collaborate), (continous presence) - ekran terminala wideokonferencyjnego dzielony jest na cztery części, na których cztery strony połączenia widzialne są jednocześnie;
Tryb z prowadzeniem (wyróżniony przewodniczący konferencji, do nadawania i odbioru informacji sygnalizacyjnej wymagane jest dodatkowe wyposażenie):
zarządzanie bezpośrednie (Direct Control) - operator mostka decyduje, która ze stron (lokalizacji) zarządzać będzie konferencją: staje się ona wówczas tzw. terminalem uprzywilejowanym, najczęściej funkcje tę pełni przewodniczący konferencji, sygnalizacja przesyłana jest w paśmie;
tryb lektorski (rozsiewczy): lektor widziany jest przez wszystkie pozostałe strony połączenia wideokonferencyjnego i może on sterować wyborem lokalizacji, którą chce mieć na wizji;
Funkcja sterowania przez przewodniczącego jest funkcją opcjonalną. Dodatkowym ułatwieniem jest możliwość numerowania terminali, uczestniczących w wideokonferencji.
Dla każdego użytkownika musi istnieć możliwość czasowego wyłączenia nadawania dźwięku lub obrazu, fakt ten powinien być sygnalizowany pozostałym stronom. Uwzględniając możliwość postrzegania ruchów i mimiki twarzy, wydaje się, że wystarczającym będzie wyświetlanie równocześnie 3 rozmówców na standardowym monitorze wideo. Wydaje się również, że konferencja trójstronna to sytuacja najbardziej typowa dla posiedzeń biznesowych. Patrząc z perspektywy czasu, kiedy ciężar komunikacji multimedialnej przesunął się z sieci szerokopasmowych na sieci nie gwarantujące jakości transmisji (QoS), a więc przede wszystkim sieci z protokołem IP zauważyć trzeba, jak dobrze w zalecenia te wpisuje się komputer osobisty jako wielozadaniowy i multimedialny terminal.
Telekomunikacja multimedialna jako zagadnienie techniczne
Zalecenia szkieletowe
Zalecenia definiujące usługi wideotelefoniczne specjalizowane są dla danego typu techniki dostępowej / sieci transmisyjnej. ITU - T zdefiniowało dostęp do usług audiowizualnych poprzez:
cyfrową sieć z integracją usług (ISDN);
standardową sieć telefoniczną (PSTN);
sieci pakietowe nie gwarantujące jakości usług;
sieci pakietowe z gwarancją jakości usług.
I tak zalecenie:
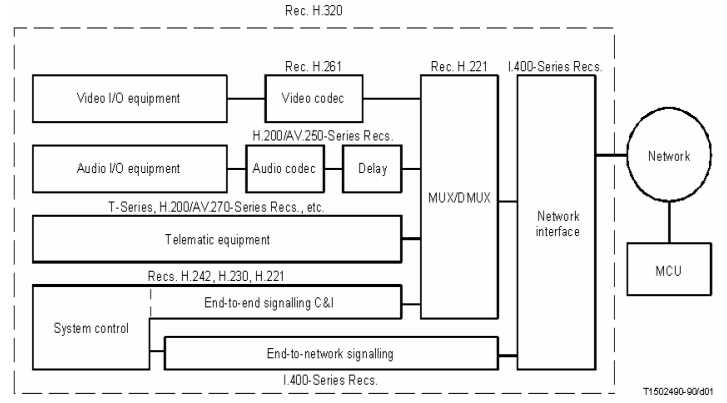
H.320 - opisuje usługę wideotelefonii realizowaną poprzez wąskopasmowe sieci komutowane o paśmie 64 kbit/s do 2 Mbit/s (np. ISDN), zdefiniowaną w serii zaleceń H.200/AV.120;
Terminal wideotelefoniczny H.320 - specjalizacja bloków.
H.321 oraz H.310 - definiuje usługę wideotelefonii w szerokopasmowych sieciach z integracją usług (sieciach B - ISDN oraz ATM); określają sposób adaptacji sygnału wideotelefonicznego H.320 do zwiększonej przepływności dla ATM oraz B - ISDN (w H.310 zalecany jest standard kompresji MPEG-2);
H.322 - określa sygnał wideotelefoniczny, zoptymalizowany dla połączeń synchronicznych w sieciach LAN, zapewniających jakość transmisji (QoS);
H.323 - definiuje zasady przebiegu połączeń wideokonferencyjnych w sieciach niegwarantujących jakości transmisji (Ethernet, Token Ring, IP);
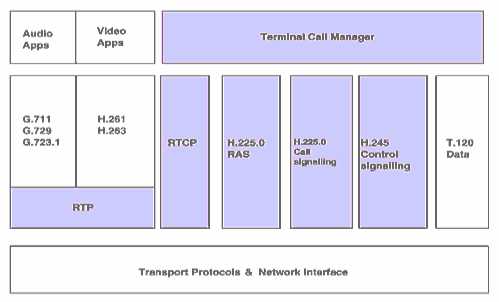
Zestaw
protokołów terminala wideotelefonicznego H.323.
zalecenie to określa dodatkowo oprócz funkcji terminala wideotelefonicznego, funkcje gatekeeper'a, "mózgu sieci H.323", pozwalającego administratorowi sieci lokalnej LAN rezerwować przepustowość kanału, wymaganą dla konferencji i poszczególnych użytkowników, a także sterować konferencjami; do dalszych zadań gatekeeper'a należy: adresowanie, translacja adresów (np. z numeracji telefonicznej E.164 na aliasy, adresy IP itd.), autoryzacja oraz autentyfikacja terminali (dopuszczenie do udziału w połączeniu tylko terminali wcześniej zarejestrowanych) i bram; zarządzanie siecią (obszarem), kierunkowanie wywołań, zaliczanie, bilingowanie, mogą one również zajmować się usługami routingu sygnalizacji rozmównej (jest to opcja korzystna, umożliwia bowiem inteligentny routing, zapewniający np. równomierność obciążenia sieci). Instalacja aplikacji gatekeeper'a w sieci LAN wymagana jest w przypadku:
eksploatacji bramy (gateway'a) H.323 lub MCU;
dynamicznego sterowania pasmem dla aplikacji wideo;
konieczności dysponowania adresami punktów abonenckich, celem obsługi połączeń e – mail;
Jeżeli pasmo, przeznaczone do celów wideokonferencji jest stosunkowo małe, gatekeeper nie jest obowiązkowy. Jeżeli wymagane jest tylko sterowanie terminalami końcowymi H.323, wystarczy ulokować aplikacje sterujące na serwerze LAN. Natomiast, kiedy w sieci zainstalowane są MCU lub brama H.32x, należy skorzystać z aplikacji sterujących, udostępnionych wraz z wyposażeniem przez ich producenta.
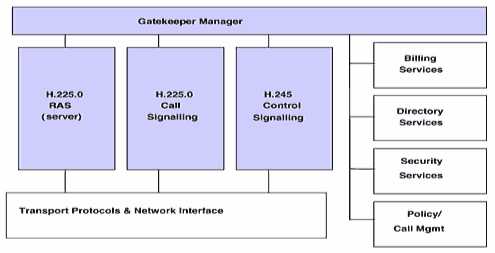
Budowa
gatekeeper'a H.323.
funkcje bramy (geteway'a) pomiędzy siecią lokalną LAN a siecią wąskopasmową wg zalecenia H.320, gwarantującą współpracę aplikacji H.323 z innymi terminalami serii H.32x;
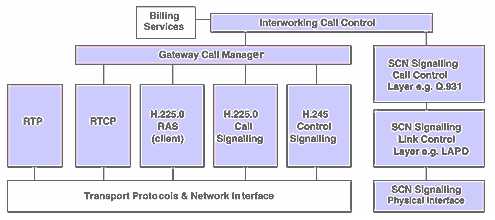
Zestaw
protokołów bramy H.323 (gateway'a).
funkcje urządzenia do sterowania wielodostępem, czyli tzw. mostka wideokonferencyjnego MCU, które zajmuje się negocjowaniem pomiędzy terminalami standardów kodeków audio i wideo oraz obsługa strumienia danych multimedialnych. Typowa aplikacja MCU posiada od 4 do 48 portów, przy czym tylko część z nich wykorzystywana jest do realizacji przekazu multimedialnego (sygnałów dźwięku, obrazu i danych), pozostałe służą do zestawiania indywidualnych połączeń telefonicznych. Dodać należy, że mostek wideokonferencyjny MCU obligatoryjnie obsługiwać musi transmisję dźwięku (jest on do tego celu wyposażony w miksery dźwiękowe), natomiast transmisja obrazu (wymagająca dodatkowego wyposażenia mostka w przełącznice wizyjne) i danych są funkcjami opcjonalnymi.
W MCU (MCS) funkcjonalnie rozróżnia się dwa bloki: MC (Multipoint Controller), odpowiedzialny za komunikację wielopunktową oraz MP, który zapewnia obsługę wspólnego transferu sygnałów audio, wideo oraz danych. NA podstawowe wyposażenie MCU składa się MC, bloki MP, w różnej liczbie, stanowią wyposażenie dodatkowe.
MCU = MC ( + n MP)
W funkcje MC może być opcjonalnie wyposażony terminal H.323.
Standard H.323 zaleca używanie w terminalach wideotelefonicznych H.323 protokołu RTP (Real Time Protocol), zapewniającego transmisje w czasie rzeczywistym sygnałów audio i wideo, wymagane jest realizowane sprzętowo priorytetowanie ruchu H.323 w sieci pakietowej;
H.324 umożliwia zestawianie połączeń wideotelefonicznych przez zwykłe, analogowe, komutowane linie telefoniczne SCN: Switched Circuit Network (za pośrednictwem modemu, gwarantującego przepływności 28.8 kbit/s i mniejsze - do 9,6 kbit/s). Aby umożliwić realizację wideokonferencji w warunkach tak małej dostępnej przepływności potrzebne były nowe standardy kompresji dźwięku (G.723.1, redukujący wymaganą dla audio prędkości transmisji do 5,3 / 5,3 kbit/s) oraz obrazu (H.263, zapewniające bardziej rozbudowane mechanizmy kompresji ruchu przy większym formacie obrazu, jakość uzyskiwana lepsza jest od jakości zapewnianej przez H.261 nawet dla większych przepływności).
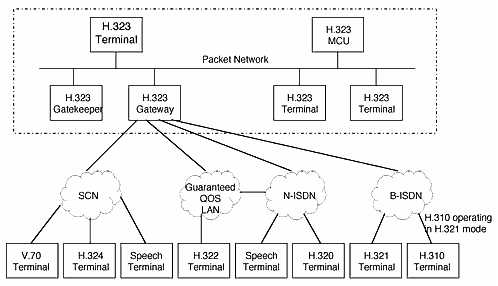
Współpraca
terminali różnych standardów.
Wszystkie z powyższych zaleceń nazywane są zaleceniami szkieletowymi, ponieważ w wielu zagadnieniach odwołują się do innych, powstałych wcześniej standardów. I tak np. sposób kodowania sygnału wizji oraz sygnału głosowego określane są poprzez podanie odpowiedniego zalecenia.
Sygnały składowe
W sygnale wideotelefonicznym wyróżnia się następujące sygnały składowe:
Sygnały dźwiękowe (audio signals) tworzące ciągły strumień danych, wymagający transmisji w czasie rzeczywistym (można wprowadzić funkcję aktywacji głosowej (voice activation) celem zmniejszenia wymaganej przepływności sygnału).
Sygnały wideo (video signals) generują ciągły strumień danych, dla którego zapewnić należy najwyższą możliwą prędkość transmisji dla uzyskania maksymalnej jakości, dostępnej przy danej przepływności kanału.
Sygnały sterujące (control signals) obejmują informacje sterujące, przesyłane pomiędzy terminalem a siecią w kanale D. Kanał dla sygnalizacji pomiędzy dwoma terminalami udostępniany jest tylko w przypadku zaistnienia takiej potrzeby, według mechanizmu zgodnego z zaleceniem H.221, tj. w obrębie kanału BAS (Bitrate Allocation Signal) lub w kanale serwisowym (service channel).
Sygnały transmisji danych (data signals) czyli obrazy nieruchome, dokumenty, transmisje sygnału faksowego. Sygnały transmisji danych są sygnałami dodatkowymi, dlatego transmitowane mogą być tylko w ograniczonych przedziałach czasowych, zastępując całość lub część sygnału audiowizualnego. Transmisja danych poprzedzana jest negocjacją warunków transmisji pomiędzy terminalami, ponieważ jest to funkcja opcjonalna i wymaga dodatkowego wyposażenia terminala wideokonferencyjnego.
Systemy kodowania sygnałów audio i wideo oraz inne zagadnienia techniczne typowe dla usług audiowizualnych znajdują się w innych rekomendacjach serii H.200/AV.200, tzw. zaleceniach uzupełniających.
Zalecenia uzupełniające
Różne:
H.211 - struktura ramki dla transmisji audiowizualnej dla kanałów 64kbit/s do 1920 kbit/s (łącza komutowane i dzierżawione);
H.231 - zawiera specyfikację mostka wideokonferencyjnego (serwera multikonferencji) MCU (Multipoint Control Unit);
H.233, H.234 - kryptografia w wideokonferencji;
H.242 - definiuje sposób nawiązywania połączenia oraz warunki dopuszczalności dynamicznej zmiany parametrów w czasie trwania połączenia;
H.243 - precyzuje sposoby nawiązywania połączeń wielopunktowych;
Kodowanie wideo:
H.261 - algorytmy kompresji obrazu CIF (Common Intermediate Format) oraz QCIF (Quarter CIF). Uwzględnienie standardu kodowania QCIF (zapewniającego rozdzielczość sygnału luminancji 144 linii, 176 elementów oraz 72 linie, 88 elementów dla każdego z sygnałów chrominancji) jest dla terminali wideokonferencyjnych obligatoryjne (strumień wejściowy kodera ma prędkość transmisji 9,1Mbit/s), natomiast standard CIF (rozdzielczość sygnału luminancji: 288 linii, 352 elementów; 144 linie, 176 elementów każdego ze składowych sygnałów chrominancji) jest opcjonalny (strumień wejściowy kodera o przepływności 36,5 Mbit/s);
H.263 - kompresja według algorytmu SQCIF (QCIF).
Kodowanie audio:
Stosowane / zalecane metody kompresji dźwięku, stosowane w systemach wideotelefonicznych, generują ciągły strumień danych o stałej prędkości binarnej (CBR) i nie posiadają detektora ciszy.
Zalecenie G.711 - definiuje kompresję sygnału audio w paśmie telefonicznym:
300 – 3400 Hz o przepustowości 64 kbit/s.
Standard ten dominuje aktualnie. Jest on zdatny dla wszystkich sygnałów przesyłanych w sieci komutowanej: sygnału mowy, sygnalizacji wieloczęstotliwościowej DTMF oraz sygnałów transmisji danych (przy redukcji liczby poziomów kwantyzacji do 127 (co odpowiada 7 bitom na próbkę) i daje w efekcie sygnał o przepływności 56kbit/s). Standard ten zapewnia jedynie kwantyzację skalarną.
Zalecenie G.722 - dla sygnałów audio w paśmie 50 – 7000 Hz, kodowanych z przepływnością 64kbit/s, 56 kbit/s lub 48 kbit/s.
Wykorzystywana jest metoda kodowania podpasmowego. Kompresowany sygnał dzielony jest (z użyciem filtrów QMF - kwadraturowych filtrów lustrzanych) na dwa podpasma: pasmo małych częstotliwości (do 4 kHz) i pasmo powyżej częstotliwości 4 kHz, następnie zaś poddawany kodowaniu adaptacyjnemu DPSM(?) (kompresji ADPCM). Górne pasmo kodowane jest 4 - poziomowo, dolne zaś zależnie od dostępnej w systemie przepływności: 60 - poziomowo (dla 64kbit/s), 30 - poziomowo (56kbit/s) lub 15 - poziomowo (48kbit/s). Jakość uzyskiwana przy kodowaniu G.722 wyższa jest niż dla kodowania wg zalecenia G.711;
Zalecenie G.723 - zapewnia kodowanie sygnału o szerokości pasma 4 kHz z przepływnością 40 kbit/s, 32 kbit/s lub 24 kbit/s;
Zalecenie G.723.1 - dostosowane do potrzeb standardu H.324 w sieciach z transmisją modemową, korzystający (kto korzysta z algorytmu (zalecenie (podejrzewam ...)- korzystające)G.723.1 czy (standard - korzystający)H.324?) z algorytmu ACELP, zapewnia przepływności sygnału audio 5,3 / 6,4 kbit/s.
Zalecenie G.728 - pozwala na skompresowanie sygnału wejściowego o szerokości pasma 300 - 3400 Hz do sygnału cyfrowego o przepływności 16 kbit/s (wynikowe opóźnienie jest mniejsze niż 2 ms).
Jakość sygnału otrzymywanego po zastosowaniu tej metody kompresji porównywalna jest z bardzo dobrej jakości sygnałem telefonicznym. Tak duże ograniczenie wymaganej prędkości transmisji możliwe było dzięki zastosowaniu kodera predykcyjnego o małym opóźnieniu LDCELP (LowDelay Code Excited Linear Prediction), działającego według zasady adaptacji wstecz. Ramka sygnału mowy, składająca się z pięciu próbek, kodowana jest na dziesięciu bitach: 7 bitów przenosi kod z tablicy kształtów sekwencji pobudzenia, 3 pozostałe bity - definiują wzmocnienie. Standard ten może być również stosowany do transmisji szerokopasmowej, zakodowany strumień mowy ma wówczas przepływność 32 kbit/s;
Zalecenie G.729 - z użyciem algorytmu CS - ACELP (Conjugate Structure - Algebraic CELP) zapewnia dalsze ograniczenie wymaganej przepływności dla sygnału audio do 8 kbit/s.
Dodatkowo zdefiniowano rodzinę zaleceń T.120, obejmujących usługi dodatkowe w ramach telekonferencji, jak transport innych sygnałów (faks, dane), dostęp do aplikacji etc. Minimalnym zestawem zaleceń dla zapewnienia funkcjonowania terminala lub MCU, jest grupa zaleceń T.122 – T.125. Rodzina zaleceń T.120 opisuje metody współdzielenia aplikacji i dokumentów;
T.122 zajmuje się obsługą połączeń wielopunktowych;
T.123 opisuje protokoły transmisji sieciowej;
T.124 określa podstawową kontrolę konferencji;
T.124 odpowiada za zarządzanie wideokonferencją, terminali do transmisji danych oraz dźwięku i obrazu, jak również MCU.
Razem z pozostałymi zaleceniami serii T.120 zapewnia mechanizmy zestawiania i sterowania konferencją.
T.126 omawia zasady wymiany obrazów nieruchomych;
Definiuje przesyłanie obrazów nieruchomych, skojarzonych adnotacji, wskaźników oraz zdarzeń po stronie zdalnej (wprowadzanych z klawiatury) tak, aby terminale mogły implementować podstawowe współdzielenie aplikacji komputerowych.
Kodowanie sygnałów audio
Terminal zgodny z normami ETSI powinien poprawnie odbierać sygnały kodowane G.711 (według prawa A oraz prawa (?)). Może się jednak zdarzyć, że realizowane jest kodowanie tylko według jednej z tych krzywych kompandorowania lub żadnej (informacja ta zawarta jest w opcjach terminala (capability set)).
Kodowanie sygnałów wideo
Obowiązkowo wymagane jest kodowanie QCIF (Quarter Common Interchange Format), dodatkowo może być również zapewnione CIF (Common Interchange Format). Dla każdej metody kodowania QCIF oraz CIF podawana jest wartość minimalnego odstępu pomiędzy kolejnymi obrazami MPI (Minimum Picture Interval), gdzie MPI: 1 / 29.97s; 2 / 29,97 s; 3 / 29.97s; 4 / 29.97s.
Przepływność
Podanie w deklaracji własności możliwości transmisji kanału o wyższej przepływności, np. 2H0 implikuje zdolność do transmisji kanału o niższej przepływności, w przytoczonym przypadku 1H0. Analogicznie dla innych parametrów: spełnienie wymagania po prawej stronie znaku "<" gwarantuje spełnienie wymagania dla wszystkich wartości znajdującej się po lewej stronie tegoż znaku (prezentuje to zamieszczona poniżej tabela hierarchii deklaracji własności). Hierarchia deklaracji własności terminala (capabilities):
G.711 (z prawem A lub (mi?), lub obydwoma)(?) < G.722 - 48 G.711 (z prawem A lub mi(?), lub obydwoma)(?) < G.728 1B < 2B < 3B < 4B < 5B < 6B 1H0 < 2H0 < 3H0 < 4H0 < 5H0 QCIF < CIF 4 / 29,97 <... < 1 / 29,97
Zdolność do transmisji danych nie podlega szeregowaniu, tj. zapewnione są tylko deklarowane explicite opcje:
LSD - małej przepływności (Low Speed Data);
HSD - dużej przepływności (High Speed Data);
MLP - z protokołem wielowarstwowym (Multi - Layer Protocol);
HS - MLP - dużej przepływności z protokołem wielowarstwowym (High Speed -MLP).
Zestaw deklaracji własności zaczyna się znacznikiem deklaracji: (111) [24], po którym następują wszystkie deklarowane własności (bez powtórzeń, możliwe jest tylko dwukrotne podanie wartości MPI, kolejno dla QCIF oraz CIF) dotyczące parametrów, które w danej chwili powinny być w odbiorniku zmienione (dopuszcza się następujące wartości: : (100) [1 31] lub (101) [0 31] oraz rozszerzające kody ESCAPE). Zestaw może być powtarzany nieograniczoną ilość razy lub zakończony przesłaniem jednego z rozkazów. Pole deklaracji własności nigdy nie może być puste, musi znajdować się w nim definicja przynajmniej jednej opcji (capability), oprócz znacznika deklaracji (capability marker: (111)[24]). W jednej ramce nie mogą znajdować się dwa znaczniki. Zmiana deklarowanych własności odbyć może się dopiero po skompletowaniu aktualnie przesyłanego zestawu, a następnie wysłaniu przynajmniej jednego rozkazu.
Zalecenie H.323
Pierwsza wersja standardu H.323, nie gwarantująca jeszcze jakości transmisji pojawiła się w październiku 1996 roku. Koncentrowała się ona na funkcjach terminala wideotelefonicznego oraz wyposażeniu sieci LAN. Pojawienie się technologii "głosu po pakiecie" (Voice over IP, VoIP) wymusiło konieczność rewizji przyjętych założeń; powstałą np. konieczność zdefiniowania komunikacji pomiędzy aplikacją telefoniczną, zainstalowaną na PC a standardowym terminalem telefonicznym w sieci komutowanej. Powstała potrzeba standaryzacji telefonii IP. Druga wersja standardu H.323 powstała w styczniu 1998. Dodanie kolejnych funkcji, takich jak transmisja faksowa w pakietowej, komunikacja pomiędzy aplikacjami gatekeeper'ów oraz mechanizmów szybkich połączeń zapoczątkowały ewolucję w kierunku wersji trzeciej.
Jednym z celów powstania tego standardu było zapewnienie współpracy z innymi sieciami multimedialnymi (funkcje te spełnia gateway H.323) Wyróżnia się następujące typy topologii w połączeniach wideokonferencyjnych H.323 wielopunktowych:
a)(?) scentralizowany - z mostka wideokonferencyjnego do każdego z terminali końcowych zestawione jest połączenie typu punkt – punkt, umożliwia to połączenie stacji końcowych, używających różnych schematów kodowania i transmitujących z różnymi przepływnościami;
b)(?) zdecentralizowany - o ile nie jest wymagana dodatkowa transmisja danych, sygnały z terminali transmitowane są bezpośrednio do punktu przeznaczenia, bez udziału MP, funkcje MC może w tym przypadku pełnić jeden z terminali;
c)(?) hybrydowy - MCU stanowi łącznik pomiędzy częścią z transmisją zdecentralizowaną a scentralizowaną. Można wyróżnić takie przypadki, jak:
scentralizowaną transmisję audio (sygnał wideo przesyłany bezpośrednio)
lub odwrotnie.
Zalecenie H.225 definiuje funkcje rejestracji, administracji i statusu RAS (Registration, Admission, and Status). (H.323) RAS jest protokołem pomiędzy punktami końcowymi (terminalami i gateway'ami) a gatekeeper'ami. RAS używany jest dla wykonywania procedur rejestracji, określania trybu połączenia, zmiany pasma w trakcie sesji, generowania raportów o statusie wymiany danych użytkownika, kontroli dostępu, statusu oraz rozłączania pomiędzy punktami końcowymi a gatekeeper'ami. W kanale RAS wymieniane są komunikaty RAS. Kanał RAS zestawiany jest pomiędzy punktami końcowymi a gatekeeper'em przed zestawieniem jakichkolwiek innych kanałów.
Zalecenie H.225 - Sygnalizacja rozmówna (H.323)
Opisywana zaleceniem H.225 sygnalizacja używana jest do zestawienia połączenia pomiędzy dwoma punktami końcowymi H.323, poprzez wymianę komunikatów protokołu H.225 w kanale sygnalizacji rozmównej. Rozróżnia się bezpośrednią sygnalizacją rozmówną (kiedy komunikaty wymieniane są bezpośrednio pomiędzy punktami końcowymi) oraz sygnalizacje rozmówną z routingiem przez gatekeeper'a, o wyborze metody decyduje gatekeeper w fazie wymiany komunikatów dostępu RAS. Zalecenie H.245 - Sterowanie (H.323) Sygnalizacja zdefiniowana w zaleceniu H.245 używana jest do przenoszenia informacji sterującej dotyczącej:
wymiany deklaracji właściwości / możliwości / opcji (capabilities);
tworzenia i zamykania kanałów logicznych (jednokierunkowych), używanych do przenoszenia strumieni multimedialnych;
komunikatów kontroli przepływu;
ogólnie rozkazów i wskazań.
Kanał sterowania H.245 stanowi kanał logiczny i w przeciwieństwie do kanałów transmisji danych, jest on stale zestawiony.
RTP
Używany w standardzie H.323 protokół RTP - wykorzystujący struktury zdefiniowane zaleceniem H.245 oraz IP - multicast - stosowany jest do zapewnienia funkcji multicastingowych (transmitowania treści do kilku wybranych punktów). Multicast - w przeciwieństwie do innych realizowanych w sieci IP usług:
unicast'u (transmisji punkt - punkt pomiędzy jednym nadawcą a jednym odbiorcą) oraz
broadcast'u (obejmującego wszystkie komputery w lokalnej podsieci w obrębie zadanej klasy adresowej A ,B lub C) - pozwala na adresowanie wybranych terminali w obrębie klasy adresowej D (ustawienie najbardziej znaczących bitów MSB = "1110"), co odpowiada adresom od 224.0.0.0 do 239.255.255.255.
Adres multicastowy IP nie jest związany z konkretnym, fizycznym terminalem, a z daną sesją (nadawanym ciągiem pakietów), wybiera go (np. 231.254.12.187) nadawca informacji, poszczególni odbiorcy mogą dołączać się do definiowanej za pośrednictwem tego adresu grupy. Rutery do realizacji funkcji multicast wymagają programu rutingu multicastowego:
mrouted; w ruterach bez funkcji multicastingu nie wywołują one reakcji.
Pakiety multicastowe tunelowane są przez sieć pomiędzy ruterami multicastowymi, zakodowane jako unicast, tworzy się wirtualna sieć MBONE (Multicast Backbone). Wartość TTL zmniejszana jest tylko przez rutery multicastowe (mrouted); wartość TTL wymagana do przekroczenia tzw. punktów krytycznych - a więc granicy danej podsieci - jest stosunkowo wysoka:
32 dla sieci miejskiej,
64 dla regionalnej,
128 - dla kontynentalnej.
RTP zastępuje typowe dla sieci pakietowych bez gwarancji jakości połączeń protokoły TCP (Transmission Control Protocol) / UDP (User Datagram Protocol). RTP realizuje takie funkcje jak:
identyfikacja typu transmitowanych danych (payload-type identification),
numerację sekwencji przesyłanych danych,
timestamping oraz monitorowanie transmisji, np. wykrywanie natłoku.
Funkcje transmisyjne dla protokołu RTP realizuje UDP lub inny protokół transmisyjny, zapewniając multipleksację oraz kontrole poprawności transmisji (CRC). Do jego podstawowych zalet należą:
zapewnianie poprawnej kolejności przesyłanych informacji,
brak powtórzeń i zagubień, nie gwarantuje on jednak bezbłędnej transmisji.
Jego następcą, nie posiadającym tego mankamentu, a więc zapewniającym również jakość transmisji pakietu, jest będący w opracowaniu MTP: Multicast Transport Protocol.
RTCP (Real-time transport control protocol) stanowi integralną część RTP, odpowiedzialną za sterowanie. Podstawowym zadaniem RTCP jest zapewnienie informacji zwrotnej o jakości transmitowanych / dystrybuowanych danych. Oprócz tego RTCP przenosi identyfikator warstwy transportowej źródła RTP (nazywany też "nazwą kanoniczną"), który potrzebny jest w odbiornikach do synchronizacji sygnałów audio i wideo.
//Definicja usług wideotelefonii i wideokonferencji 2. Metody dostępu do medium (kanału radiowego) w standardzie 802.11b. //SISF DISF (szczeliny czasowe (VoIP nie daje ściągać)) 2.1 Metoda regulacyjna dostępu CSMA/CA - DCF
// wlan.pdf
3.2.4 Rozproszona funkcja koordynacji DCF
Podstawowa metoda dostępu do łącza w standardzie 802.11 została nazwana trybem z rozproszoną funkcją koordynacji - DCF (ang. Distributed Coordination Function). Jest to metoda dostępu do medium zasadniczo oparta o algorytm rywalizacyjnego dostępu z unikaniem kolizji - CSMA/CA (ang. Carrier Sense Multiple Access with Collision Avoidance).
Algorytm CSMA/CA jest bardzo podobny do algorytmu rywalizacyjnego dostępu z wczesnym wykrywaniem kolizji - CSMA/CD (ang. Carrier Sense Multiple Access with Collision Detection) stosowanym w przewodowych sieciach Ethernet. Oba wymienione typy protokołów dostępność do transmisji w medium wykrywają poprzez śledzenie i wykrywanie nośnej. Ubieganie się o dostęp do medium jest rozstrzygane przy wykorzystaniu eksponencjalnego algorytmu z losowym odstępem między ramkami (backoff). Protokół CSMA/CA wykorzystuje sterowanie rozproszone w przeciwieństwie do zcentralizowanego sterowania dostępem stosowanego w przewodowych sieciach LAN. Zatem stacja może transmitować, "kiedy sobie życzy" i tak długo jak przestrzega reguł protokołu.
W CSMA, stacja która ma pakiet do transmisji najpierw sprawdza stan łącza, a w wypadku jego zajętości prze inne stacje wstrzymuje się z transmisją i ewentualnie czeka na zwolnienie kanału. Jeżeli na podstawie informacji pomocniczych o stanie kanału poprzez śledzenie nośnej stwierdza, że kanał jest wolny przez okres czasu dłuższy niż DIFS pakiet jest transmitowany w trybie natychmiastowym. Podwarstwa MAC działa w połączeniu z warstwą fizyczną oszacowując stan medium. Metoda ta pozwala na pomiar poziomu sygnału radiowego w celu określenia poziomu wzmocnienia odbieranego sygnału. Jeżeli odbierany sygnał znajduje się poniżej określonego progu, medium jest zadeklarowane jako do oceny i podwarstwa MAC nadaje status dla transmisji pakietów jako stan oceny kanału CCA (ang. Clear Channel Assessment). Inną metodą korelacji odbieranego sygnału z 11- bitowym (chip) kodem Barker'a wykrywa obecność właściwego sygnału DSSS. Obie metody mogą być zastosowane jako kombinacja w celu zapewnienia większej niezawodności poprawnego oceniania bieżącego statusu medium.
3.2.4.1 Unikanie kolizji
Protokół CSMA z unikaniem kolizji (CA) wprowadza losowe odstępy między kolejno transmitowanymi pakietami. Unikanie kolizji jest wymagane w celu redukcji wysokiego prawdopodobieństwa kolizji natychmiast po pomyślnej transmisji pakietu. Zasadniczo jest to próba separacji całkowitej liczby transmitujących stacji w mniejsze grupy, z których każda używa różnych długości szczelin czasowych (znanych jako ang. backoff time slot). Jeżeli medium jest wykryte jako zajęte stacja musi po pierwsze opóźnić nadawanie do czasu zakończenia interwału czasu - DIFS i dalej czekać na losową liczbę określającą przedział czasu oczekiwania (nazywanej interwałem "backoff") zanim podejmie próbę transmisji. Opisana sytuacja została zobrazowana na rysunku:
Rys. 3.14. Transmisja pojedynczego pakietu z użyciem protokołu CSMA/CA
3.2.4.2 Wykrywanie kolizji i wykrywanie błędów
Mechanizm wykrywania kolizji wykorzystywany w przewodowych sieciach LAN wymaga od odbiornika ciągłego śledzenia transmisji w medium i wykrywania, kiedy realizowana jest w nim transmisja. Tego typu mechanizmy nie mogą być bezpośrednio wykorzystane w sieciach bezprzewodowej z kilku powodów. Po pierwsze w sieciach przewodowych różnice pomiędzy poziomami sygnałów nadawczych i odbiorczych (dynamika sygnału) jest mała i umożliwia łatwe wykrywanie kolizji.
W środowisku bezprzewodowym emitowana energia sygnału jest promieniowana we wszystkich kierunkach i odbiorniki muszą charakteryzować się bardzo dużą czułością, żeby odebrać sygnał. Nie bez znaczenia jest fakt, że odbiornik znajduje się w bezpośredniej bliskości nadajnika. Powoduje to, że kiedy dwa lub więcej węzłów nadaje w tym samym czasie występujące kolizje będą trudno wykrywalne, ponieważ poziom transmisji sygnału od wysyłającego węzła przekracza poziom transmisji sygnałów od innych węzłów. Co więcej, podstawowym założeniem dla wykrywania kolizji jest to żeby wszystkie węzły były w zdolne "słyszeć" siebie nawzajem. Tego typu wymaganie jest mało praktyczne w środowisku bezprzewodowym, ponieważ mocno osłabiony i zmienny sygnał czyni wykrywanie kolidujących ze sobą pakietów jako trudne. Sytuację pogarsza zjawisko "stacji ukrytej".
Zjawisko stacji ukrytej występuje, kiedy nie wszystkie stacje mają bezpośrednią łączność. Stacja jest "ukryta", jeżeli znajduje się w zasięgu stacji odbierającej dane, ale jest poza zasięgiem stacji nadającej. Stacja "A" nadaje do stacji "B". Ponieważ stacje "A" i "C" znajdują się poza swoim zasięgiem transmisja nie zostanie wykryta w stacji "C". Stacja "C" przyjmuje, że łącze jest wolne i może rozpocząć transmisję do stacji "B" lub "D". Transmisja ta powoduje w stacji "B" kolizję z danymi ze stacji "A". Taka sytuacja powoduje z kolei spadek przepustowości łącza w skutek konieczności częstych retransmisji.
W końcowym efekcie wykrywanie kolizji wymaga dwukierunkowych i kosztownych implementacji tj. pełno dupleksowy radionadajnik pozwalający na nadawanie i odbiór w tym samym czasie.
W sieciach WLAN zastosowano rozbudowany algorytm CSMA, który został nazywany protokołem dostępu CSMA/CA. Protokół ten stanowi odmianę protokołu CSMA bądź CSMA/CD (IEEE 802.3), którego elementy ze względu na wspomniane powyżej wady, uniemożliwiają jego zastosowanie w kanałach radiowych. Protokół dostępu CSMA/CA posiada szereg nowych elementów, do których należą:
• zróżnicowane czasy opóźnień (w podejmowaniu różnych działań protokolarnych), dostosowane do priorytetów przesyłanych wiadomości;
• specjalne pakiety (ramki) sterujące: RTS (ang. Request To Send) i CTS (ang. Clear To Stnd), pozwalające na wstępną rezerwację medium i szybsze rozwiązywanie ewentualnych kolizji;
• liczniki czasu wyznaczające narzucone protokołem DFW działania stacji.
W omawianym standardzie (protokół 802.11 MAC) zakłada się, że wszystkie jednoadresowe ramki DATA muszą być powiadamiane pozytywnie ramkami ACK (ang. acknowledgement), oczywiście, jeżeli pakiet został odebrany poprawnie. Również ramki RTS wymagają potwierdzenia ramkami CTS. Zostało to zilustrowane w części a) rysunku 3.15.
Rys. 3.15. Wymiany ramek między stacją źródłową i docelową (a) oraz potwierdzana transmisja pakietów danych w trybie "punkt-punkt"
Ramki RTS i CTS są szczególnie użyteczne w sytuacjach, gdy:
• istnieje potrzeba przesyłania długich pakietów DATA, bądź też;
• w sieci mamy do czynienia z tzw. stacjami ukrytymi, tj. znajdującymi się poza zasięgiem bezpośredniej słyszalności stacji (sieć z transmisją wieloetapową). Istnienie stacji ukrytych (ang. hidden stations) w sposób istotny obniża efektywność algorytmów CSMA. Niekorzystny wpływ stacji ukrytych na jakość protokołu DSMA może być znacznie ograniczony poprzez zastosowanie algorytmu DCF z opcjonalnym wykorzystaniem ramek (pakietów) RTS/CTS.
Potwierdzenie ACK jest transmitowane zawsze po szczelinie SIFS, która każdorazowo trwa krócej niż DIFS co pozwala na transmitowanie ramek ACK przed każdym nowym pakietem. (rysunek 3.15b). W sytuacji kiedy nie zostanie otrzymane potwierdzenie ramki, nadajnik zakłada, że pakiet jest zagubiony/ niepoprawny (np. wystąpiła kolizja lub błąd transmisji) i retransmituje pakiet. Retransmisja jest realizowana przez podwarstwę MAC a nie przez wyższe warstwy, co stanowi niewątpliwą zaletę tego rozwiązania.
W bezprzewodowych sieciach LAN błędy odbioru występują częściej niż w przewodowych sieciach LAN. Zastosowanie potwierdzeń ACK zmniejsza efektywną szybkość transmisji, ale jest nieodzowne w kanałach radiowych. Potwierdzanie ACK jest wymagane jedynie dla wymiany typu "punkt - punkt". Potwierdzenie dla ruchu rozgłoszeniowego i wielopunktowego nie jest wymagane, gdyż jest uznawane jako mało efektywne (np. z powodu częstego występowania kolizji potwierdzeń).
3.2.4.3 Wirtualne wykrywanie
Protokół CSMA/CA - może być rozszerzony poprzez włączenie wirtualnego mechanizmu wykrywania nośnej, który dostarcza informacje związanej z rezerwacją poprzez ogłaszanie zapowiedzi o zbliżającej się możliwości wykorzystaniu medium bezprzewodowego. Realizacja tej funkcji odbywa się przez wymianę krótkich pakietów sterujących nazywanych RTS i CTS (por. powyżej). Pakiety RTS są wysyłane przez stację nadającą, podczas gdy pakiety CTS są wysyłane przez stację odbiorcy przyznając stacji żądającej pozwolenie na transmisję. (rysunek 3.16).
Rys. 3.16. Transmisja pakietu typu punkt-punkt z wykorzystaniem wirtualnego wektora zajętości kanału
Pakiety RTS i CTS zawierają pola, które definiują okres czasu rezerwacji medium dla transmisji pakietu danych i pakietu ACK. Pakiety RTS i CTS minimalizują występowanie stanów kolizyjnych i pozwalają także stacji nadającej na szybkie ocenianie przypadków występowania kolizji. Dodatkowo, pakiet CTS alarmuje sąsiednie stacje (te, które znajdują się w jej zasięgu odbiorczym a nie nadawczym), aby powstrzymały się z nadawaniem pakietów do tej stacji, w ten sposób redukując kolizje związane z występowaniem zjawiska stacji ukrytej. Opisana sytuacja została zobrazowana na rysunku 3.17 (a).
Rys. 3.17. a) Transmisja pakietów RTS, b) Transmisja pakietów CTS
W ten sam sposób pakiet RTS zabezpiecza obszar transmisji przed kolizją, kiedy pakiet ACK jest wysyłany od stacji odbiorczej. Zatem, informacje związane z rezerwacją są dystrybuowane dookólnie. Wszystkie inne stacje, które poprawnie zdekodują pola informacyjne pakietów RTS i CTS zapamiętają informacje o rezerwacji medium w wirtualnym wektorze alokacji sieci NAV (ang. Net Allocation Vector). Dla tych stacji, NAV jest stosowany w połączeniu z wykrywaniem nośnej określającą dostępność medium. Stacje, których NAV nie ma wartości zerowej lub stan nośnej wskazuje na ich zajętość będą powstrzymywać się od nadawania.
Podobnie jak mechanizm potwierdzania ACK, rozpoznawanie wirtualne nie jest stosowane dla MPDU z adres rozsiewczym lub rozgłoszeniowym, z powodu prawdopodobieństwa kolizji ze względu na dużą liczbę pakietów CTS. Stąd, standard 802.11 pozwala na transmisje tylko krótkich pakietów bez wirtualnego wykrywania. Kontrola realizowana jest za pomocą parametru nazywanego "próg RTS". Tylko pakiety o długości większej niż próg RTS są transmitowane z wykorzystaniem mechanizmu wirtualnego wykrywania (NAV). Należy zauważyć, że efektywność algorytm wirtualnego wykrywania silnie zależy od przyjęcia założenia, że obie stacje nadawcza i odbiorcza, posiadają podobne parametry techniczne (np. moc nadawania i czułość odbiornika). Stosowanie mechanizmu wirtualnego wykrywania jest opcjonalne, lecz musi on być implementowany.
// wlan.pdf
2.2 Metoda regulowanego dostępu do kanału radiowego - PCF
// wlan.pdf
3.2.4.4 Tryb z punktową funkcją koordynacji (dostępu)
Ruch usług wrażliwych czasowo, wymaga skończonej wartości opóźnienia poza przekroczeniu, której przesyłana informacja jest pozbawiona wartości i może być odrzucona. Wymagania te wyraźnie kontrastują z wymaganiami dotyczącymi opóźnień dla ruchu danych. Dla tego typu ruchu ograniczenia w tym względzie są niższe.
CSMA/CA nie jest szczególnie predysponowany do zabezpieczenia ruchu usług wrażliwych czasowo, ponieważ traktuje wszystkie pakiety jednakowo i jako pakiety danych. Jest to cechą systemu bezpołączeniowego, nie szereguje lub nie nadaje priorytetów pakietom przenoszącym ruch wrażliwy czasowo (głos, wideo) i jako rezultat nie jest w stanie rozróżniać pomiędzy ruchem czasu rzeczywistego a ruchem nie wrażliwym czasowo (dane). Możliwość kolizji, losowy czas oczekiwań (backoff) oraz transmisje długich pakietów mogą powodować zmienność opóźnień (jitter). Podobnie jak ACK dla kolizji i wykrywanie błędów CSMA/CA może zniekształcać transmisję ruchu czasu rzeczywistego poprzez wzrost opóźnienia spowodowanego przez retransmisje.
Do eliminacji tego typu wad dla ruchu czasu rzeczywistego, jako opcja może być zastosowana funkcja punktowej koordynacji dostępu PCF. PCF stosuje, zdecentralizowany, bezkolizyjny wielopunktowy schemat dostępu, kiedy stacje są dopuszczone i posiadają zezwolenie na transmisję wydane przez punkt dostępowy AP. Należy zauważyć, że kolizje mogą występować w czasie AP transmituje wiadomości z zapytaniem do stacji mobilnych znajdujących się w obszarze zasięgu (pokrycia). Taka sytuacja pozwala innym węzłom chcących transmitować dane w trybie asynchronicznym na dostęp do medium.
Protokół MAC zmienia tryby pracy między DCF i PCF, lecz wyższy priorytet dostępu ma PCF. Pozwala to na zastosowanie koncepcji super-ramki, gdzie PCF jest aktywne w okresie bez rywalizacji.
Rys. 3.18 Współistnienie PCF i DCF w super-ramce
// wlan.pdf
2.3 Ocena porównawcza metod dostępu do łącza radiowego FDMA, TDMA, CSMA/CA // LacznoscRadiowa.doc
1.7. Metody wielodostępu stosowane w radiokomunikacji ruchomej
Wielodostęp jest ważnym problemem w systemach telekomunikacyjnych, gdy więcej niż dwóch użytkowników dzieli się wspólnym zasobem, jakim jest pasmo kanału radiowego lub wspólny kanał kablowy (miedziany lub światłowodowy). Krótko wspomnieliśmy o tym problemie opisując model typowego cyfrowego systemu telekomunikacyjnego. Obecnie rozważymy go nieco dokładniej. Skoncentrujemy się na specyfice wielodostępu w systemach radiokomunikacji ruchomej.
W systemach radiokomunikacji ruchomej wspólne zasoby, jakimi jest pasmo elektromagnetyczne są zarządzane przez ciała administracyjne takie jak: Federalna Komisja Telekomunikacyjna (FCC — Federal Communications Commission) w USA, CEPT (Conference Europeene des Postes et Telecommunications) w Unii Europejskiej, czy też Urząd Regulacji Telekomunikacji i Poczty w Polsce.
Najstarszym rodzajem wielodostępu jest wielodostęp z podziałem częstotliwości (FDMA — Frequency Division Multiple Access). W metodzie tej pasmo całkowite przypisane systemowi jest podzielone na pewną liczbę przedziałów częstotliwości, które mogą być używane w indywidualnej transmisji pomiędzy dwoma użytkownikami systemu. Mogą też być stosowane w trybie rozsiewczym. Przedziały częstotliwościowe są zwykle na tyle wąskie, aby maksymalizować liczbę stworzonych kanałów i w konsekwencji liczbę użytkowników mogących równocześnie korzystać z systemu. Z drugiej strony, kanały powinny być wystarczająco szerokie, aby zapewnić wymaganą jakość transmisji. Jeśli transmisja ma charakter analogowy, wtedy metoda FDMA jest jedyną możliwą metodą wielodostępu, ponieważ gwarantuje ona ciągły w czasie dostęp do medium transmisyjnego wymagany w transmisji sygnałów analogowych. Na rys. 1.44 zilustrowano tę metodę. Jej charakterystyczną cechą jest istnienie pasm ochronnych pomiędzy sąsiadującymi kanałami, co przyczynia się do zmniejszenia liczby możliwych kanałów i efektywności widmowej systemu. Nadajniki i odbiorniki muszą być wyposażone w wysokiej jakości filtry kanałowe. Po stronie nadawczej filtry te kształtują widmo nadawanego sygnału tak, aby mieściło się ono w paśmie kanału. Po stronie odbiorczej filtry te wydzielają widmo sygnału z pożądanego kanału ograniczając tym samym zakłócenia od innych kanałów i szumów spoza pasma. Pewien problem powstaje wtedy, gdy moce dwóch sąsiadujących ze sobą kanałów różnią się zbytnio pomiędzy sobą. Stłumione listki boczne kanału odbieranego z dużą mocą mogą mieć porównywalny poziom z poziomem listka głównego kanału odbieranego z małą mocą w tym samym paśmie, przyczyniając się do poważnego spadku jakości odbioru sygnału słabego. Tak więc wymagana jest regulacja mocy transmitowanych sygnałów, aby uniknąć tego zjawiska.

Rys. 1.44. Ilustracja wielodostępu częstotliwościowego (FDMA)

Rys. 1.45. Ilustracja metody wielodostępu czasowego TDMA
Rys. 1.46. Ilustracja zasady wielodostępu kodowego (CDMA)
Wielodostęp z podziałem czasowym (TDMA — Time Division Multiple Access) jest kolejną metodą wielodostępu (rys. 1.45). Zamiast dostępu do fragmentu pasma przydzielonego systemowi, użytkownicy mogą transmitować swoje sygnały w całym paśmie, ale jedynie przez przydzielany im okresowo ułamek czasu (rys. 1.45). Podstawową jednostką czasu jest ramka. Jest ona podzielona na pewną liczbę szczelin czasowych. Maksymalna liczba użytkowników, którzy mogą być równocześnie obsługiwani, jest równa liczbie szczelin w ramce. Zazwyczaj jednak liczba użytkowników jest nieco mniejsza, ponieważ niektóre szczeliny czasowe są stosowane w celach sterowania, synchronizacji i utrzymania systemu. Z tego powodu ramki są często organizowane w struktury wyższego rzędu takie jak wieloramki, superramki itp. Charakterystyczną cechą metody TDMA jest konieczność kompresji danych użytkownika w krótkie bloki, które mieszczą się w przypisanych szczelinach czasowych. Jeśli ramka składa się z M szczelin, wtedy szybkość transmisji wewnątrz szczeliny czasowej musi być co najmniej M razy wyższa, niż szybkość danych pojedynczego użytkownika. W konsekwencji widmo sygnału TDMA jest co najmniej M-krotnie szersze w porównaniu z widmem ciągłego sygnału danych o tej samej szybkości. Z tego więc powodu widma na rys. 1.45 są znacznie szersze niż widma charakterystyczne dla metody FDMA pokazane na rys. 1.44. Podobnie jak dla metody FDMA, w której przedziały ochronne pomiędzy kanałami są zastosowane na osi częstotliwości, metoda TDMA stosowana w systemach radiowych wymaga czasowych przedziałów ochronnych pomiędzy blokami zajmującymi sąsiadujące szczeliny czasowe. Konieczność zastosowania przedziałów ochronnych wynika ze skończonego czasu włączania i wyłączania wzmacniaczy mocy, a także z możliwości różnych czasów propagacji sygnałów płynących od użytkowników komunikujących się z tą samą stacją bazową. Podobnie jak przedziały ochronne na osi częstotliwości w metodzie FDMA, również czasowe przedziały ochronne w metodzie TDMA zmniejszają efektywność pasmową w trybie TDMA.
W praktyce często stosuje się metodę hybrydową TDMA/FDMA, w której pewna liczba kanałów częstotliwościowych zajmuje pasmo przydzielone danemu systemowi, a z kolei oś czasu każdego z tych kanałów jest podzielona na szczeliny czasowe. Takie podejście zostało zastosowane zarówno w systemach komórkowych GSMjak i amerykańskim IS-54/136 oraz japońskim PDC.
Trzecią metodą wielodostępu jest metoda wielodostępu kodowego (CDMA — Code Division Multiple Access). Wspomnieliśmy już o jej istnieniu wyjaśniając zasadę działania systemów szerokopasmowych (z rozproszonym widmem). Zauważyliśmy już wtedy, że jeśli ciągi rozpraszające są tak wybrane, że ich korelacja wzajemna jest zerowa, sygnał wybranego użytkownika może być odzyskany z mieszaniny sygnałów generowanych przez innych użytkowników przez korelację otrzymanego sygnału z wybranym sygnałem odniesienia. Wszyscy użytkownicy zajmują to samo pasmo i transmitują w sposób ciągły swoje ciągi binarne w formie pseudolosowych sekwencji modulowanych przez ich dane informacyjne. Na rys. 1.46 przedstawiono symbolicznie zasadę wielodostępu CDMA. Podkreślmy, że metoda CDMA pozwala na idealne wyodrębnienie danych transmitowanych przez poszczególnych użytkowników wtedy, gdy zastosowane ciągi rozpraszające są idealnie ortogonalne. Niestety większość kanałów radiokomunikacyjnych charakteryzuje się zjawiskiem wielodrogowości (patrz rozdział 3), które powoduje utratę ortogonalności sygnałów na wejściu odbiornika. Znalezienie dużej liczby ciągów rozpraszających, które są równocześnie wzajemnie ortogonalne oraz ortogonalne względem swoich własnych przesunięć jest niezwykle trudnym zadaniem. W konsekwencji ortogonalność ciągów rozpraszających, w szczególności po przejściu przez kanał, nie jest idealna i ma negatywny wpływ na stosunek mocy sygnału do szumu w odbiorniku oraz na uzyskiwaną stopę błędów.
CDMA, podobnie jak poprzednie metody wielodostępu, jest często używana w kombinacji z innymi metodami takimi jak FDMA i TDMA. W przypadku zastosowania CDMA/FDMA pasmo całkowite przypisane systemowi jest podzielone na pewną liczbę pasm częstotliwościowych, z których w każdym stosuje się metodę CDMA. W przypadku zastosowania CDMA/TDMA rozpraszanie oraz wielodostęp kodowy mają miejsce w wydzielonych szczelinach czasowych pozostawiając tym samym pozostałe szczeliny innym użytkownikom działającym również w trybie CDMA/TDMA.
W ostatnich latach wprowadzono kolejną metodę wielodostępu wspierającą inne powyżej przedstawione metody. Jest to wielodostęp z podziałem przestrzennym (SDMA — Space Division Multiple Access). Działanie metody SDMA opiera się na zastosowaniu matryc antenowych, które dzięki sterowaniu elektronicznemu są w stanie syntetyzować silnie kierunkowe charakterystyki antenowe. Tak więc, jeśli użytkownicy są wystarczająco odseparowani od siebie kątowo, mogą używać te same kanały częstotliwościowe, szczeliny czasowe, ciągi rozpraszające albo kombinacje powyższych w zależności od tego, jaka jest główna metoda wielodostępu stosowana w systemie. Zastosowanie metody SDMA wywiera poważny wpływ na łączną jakość działania i pojemność systemu. Będzie ona szerzej przedyskutowana w rozdziale XVIII.
// LacznoscRadiowa.doc // Sieci_bezprzwodowe_MAC.pdf obrazki // Sieci_bezprzwodowe_MAC.pdf 3. Ocena przydatności protokołu 802.11b do realizacji usługi VoWLAN // (słaba (niski transfer), ale dobry zasięg) 3.1 Ocena przydatności protokołu 802.11b do realizacji usługi VoWLAN (słaba (niski transfer), ale dobry zasięg) 4. Wnioski 4.1 Wnioski